CS149-并行计算-斯坦福大学-学习笔记
CS149-并行计算-斯坦福大学-学习笔记
- 讲师: Kayvon Fatahalian, Kunle Olukotun
- 课程录播(中英字幕,部分有误,fall 23):https://www.bilibili.com/video/BV1du17YfE5G
- 课程官网(fall 24):https://gfxcourses.stanford.edu/cs149/fall24
- 编程作业(fall24):
- 在四核 CPU 上分析并行程序性能
- 在多核 CPU 上调度任务图
- 用 CUDA 实现一个简单的渲染器
- 在 DNN 加速硬件上优化深度神经网络(DNN)性能。(实现和优化 AWS Trainium 架构的内核)
- 使用 OpenMP 处理大规模图数据
- (fall23 第 4 题)chat149: 小语言模型,用 C++ 实现基于 DNN 的 transformer 的注意力层(flash-attention)
(fall24)课程导言:
从智能手机到多核 CPU 和 GPU,再到世界上最大的超级计算机和网站,并行处理在现代计算中无处不在。本课程的目标是深入了解设计现代并行计算系统所涉及的基本原理和工程权衡,并教授有效利用这些机器所需的并行编程技术。因为编写好的并行程序需要了解关键的机器性能特征,所以本课程将涵盖并行硬件和软件设计。
目录
- 其一:Why Parallelism? Why Efficiency?
- 其二:A Modern Muti-Core Processor
- 其三:Multi-Core Architecture Part II + ISPC Programming Abstractions
- 其四:Parallel Programming Basics
- 其五:Performance Optimization I: Work Distribution and Scheduling
其一:Why Parallelism? Why Efficiency?
第一章:为什么要并行?为什么要高效率?
摘要:并行化代码的挑战、并行芯片的动机、处理器基础
Fast != Efficient
速度快,不等于效率高
如果老板给了你 100 倍的算力设备,
你却仅仅将程序加快了 2 倍,
我想你就该被开除了。“是的,让他去重修 CS149。”
demo1:第一个并行程序
案例:
- 1 人可以在 45 秒内算出 16 个数的总和。(demo1:第一个并行程序)
- 但 2 人并不能在 23 秒内算出 16 个数字的总和,而是 40 秒。
- 4 人计算 16 个数字之和的时间,优化到了 19 秒,而不是 12 秒。(demo2:扩展到 4 个“处理器”)
- 100 多人不能在 2 分钟内数清楚人数总和。(demo3:大批量并行执行)
这个案例告诉我们:
并行计算,关键不在于如何并行,如何计算(虽然这也很重要),关键在于数据传输和协同效率。
因此,我们更多的是在学习:如何传输数据,排列数据,而不是写代码或布局硬件。
什么是计算机程序? What is a computer program ?
A program is a list of processor instructions!
“程序(program)”不同于“代码(code)”。
程序,与食谱一样,应当是可执行的一系列命题(操作流程)。
计算机程序,则是“指令流”,或者叫“指令序列”。
必须是计算机认识的一系列 01 串。
处理器做了什么? What does a processor do ?
一个简化的处理器有 3 个模块:
- Fetch / Decode: 取指令、解析指令
- ALU:算数运算单元
- Execution Context:执行上下文
案例:a = x * x + y * y + z * z
这个简单的多项式运算会编译出 5 条指令
(假设使用 r1,r2,r3 寄存器,
假设不使用任何编译优化
编译优化(ChatGPT)
):
- mul r1, r1, r1
- mul r2, r2, r2
- mul r3, r3, r3
- add r1, r1, r2 ; r1 = r1 + r2
- add r1, r1, r3
我们发现,指令 4 依赖于指令 1、2;指令 5 依赖于指令 3、4。
所以,等待是必须的,即使使用 5 个 cpu,效率也不会超过 1 条 mul 指令时间加上 2 条 add 指令时间。
(这里还有寄存器最少使用原则,或最多使用原则,不做讨论)
如何进一步提高性能?
- 数学家:改进数学公式,减少乘法次数(耗时长的操作),增加加法次数(耗时短的操作),重新编写代码。
- 硬件工程师:指令重排,指令随机化,指令流水线,分支预测,多级缓存,自动并行化,自动向量化加速
- 软件工程师:编写高维度的,可并行化的程序。任务并行化,数据结构并行化,计算并行化,数据传输并行化,数据存储并行化。主动使用缓存(预存器)。
小结
- 软件:物尽其用(压榨硬件的一切性能)
- 硬件:用尽其物(挑选更好的硬件去适配软件)
编译优化(ChatGPT)
现代编译器通常会结合多种优化策略,来提高程序的执行效率。它们会根据不同的场景、硬件架构和程序的特征,选择不同的原则来优化寄存器的使用。以下是一些现代编译器普遍采用的优化原则和策略:
1. 寄存器最多使用原则(Maximizing Register Usage)
现代编译器在许多情况下倾向于使用尽可能多的寄存器,这样可以减少对内存的访问,因为寄存器的访问速度远快于内存。这个原则通常用于以下情况:
- 频繁访问的变量:如果某个变量在计算中被频繁使用,编译器会尽可能地将其保留在寄存器中,避免频繁的内存读写操作。
- 局部性原理:寄存器的使用能很好地利用数据的局部性。例如,如果某个数据在一段时间内频繁访问,它可以存储在寄存器中,而不需要每次从内存中读取。
举例:对于一个简单的多项式计算:
1 | |
编译器可能会为每个中间结果(如 x * x、y * y、z * z)分配一个寄存器,并将结果存储在寄存器中,避免额外的内存操作。
2. 寄存器分配和寄存器重命名
- 寄存器分配:编译器通过分析程序的数据流和生命周期来确定哪些变量应该保留在寄存器中。寄存器的分配不仅考虑变量的使用频率,还要避免寄存器冲突,尽可能地减少寄存器的交换和保存操作。
- 寄存器重命名:现代编译器会使用寄存器重命名技术来避免因寄存器依赖(如数据依赖)而产生的性能瓶颈。通过给同一个物理寄存器分配多个逻辑寄存器,编译器可以让多个指令并行执行,避免等待依赖关系完成。
3. 局部变量优化
现代编译器通常会通过 局部性分析 来优化寄存器的使用。局部变量是那些只在函数内部使用的变量,编译器会尽量将它们分配到寄存器中,而不是存储在栈上或堆上。特别是对于小型的、生命周期较短的局部变量,寄存器使用能显著提高性能。
举例:
1 | |
编译器可能会将 sum 和 i 变量都存储在寄存器中,以减少对内存的访问。
4. 内联扩展(Inlining)
编译器会尝试对一些小的、频繁调用的函数进行内联扩展(inline),将函数调用替换成函数的实现体。这可以消除函数调用的开销,并减少对寄存器和内存的使用,特别是在递归或频繁调用的情况下。
5. 循环优化(Loop Optimization)
编译器对循环结构进行优化,以提高寄存器的利用率和减少内存访问。例如,编译器可能会将循环展开、循环重排或循环分割,以便使计算更密集,从而减少内存的读取次数。
举例:
1 | |
编译器可能将其优化为多个操作并行执行,或者将内存访问合并,以更高效地利用寄存器。
6. 寄存器压力和溢出(Register Pressure and Spill)
现代编译器会根据寄存器的使用情况动态调整优化策略。如果寄存器使用过多,导致“寄存器压力”过大,编译器就可能将某些值溢出(spill)到栈上,特别是在寄存器资源紧张的情况下。溢出操作会影响性能,因为它需要额外的内存读写操作。
7. 自动向量化
现代编译器(如 GCC、Clang、Intel 的 ICC 编译器等)支持自动向量化。通过向量化,编译器可以将标量操作转化为 SIMD(单指令多数据流)操作,这样能够将多个计算任务并行地放到同一个寄存器组中,从而大幅提高计算效率。
举例:
1 | |
如果编译器支持向量化,它可能会将这段代码转换成可以同时加法多个元素的 SIMD 指令,使得多个数组元素能够同时在寄存器中处理,从而提高性能。
8. 多级缓存和数据局部性
现代编译器也会考虑缓存的优化,尽量减少从内存中读取的数据量,利用 CPU 的多级缓存(L1、L2、L3 缓存)。通过优化程序的数据访问模式和寄存器分配,编译器能够使数据尽可能保持在较快的缓存中,而不需要频繁访问较慢的主内存。
9. 并行计算和多核优化
在多核处理器上运行时,编译器可能会自动将程序分割成多个并行线程,使用多核的并行性来加速计算。寄存器的分配和使用会考虑到多线程并发执行的情况,确保每个线程能够高效地利用本地寄存器。
10. 指令级并行性(ILP)优化
编译器会使用一些高级技术(如指令重排、延迟槽填充、分支预测等)来优化指令级并行性。这些优化措施通过重新排列指令,减少指令间的依赖关系,从而更好地利用寄存器和其他硬件资源,提高程序的执行效率。
总结
现代编译器会综合考虑性能、内存带宽、寄存器数量、计算依赖关系等多种因素,使用寄存器最多使用原则来最大化寄存器的利用率,但也会根据具体的硬件架构和程序的特性做适当的调整。最终目标是减少内存访问、提高并行性,并通过智能的寄存器分配和优化技术提升整体性能。
其二:A Modern Muti-Core Processor
第二章:现代多核处理器
摘要:并行形式:多核、SIMD 和多线程
案例:计算 y[i]=sin(x[i])
1 | |
这段程序计算 y[i] = sin(x[i]),
N 为数组长度,
terms 则是精度(泰勒展开项个数)。
暂且不谈这段程序在优化方面,
利用了之前的计算结果来计算 x 的幂次与 j 的阶乘,
这种做法的精妙之处,
以及使用 for 循环和局部变量,而不是函数,
带来的更高程度的局部性,
也不考虑运算溢出问题。
我们只关心,如何并行化计算。
高维度并行化(调用方并行)
1 | |
其中 sinx() 的定义同上。
老师给出的代码,
实现了 main 线程和子线程并行计算一串 y[i]=sin(x[i])。
主线程计算后半段,子线程计算前半段。
用指针运算,巧妙地在调用方进行了并行化
(即老师所说“更高维度的并行化”)。
但是,并不是所有程序都能做到这样良好的并行化。
向量编程(底层并行)
AVX intrinsics
条件分支
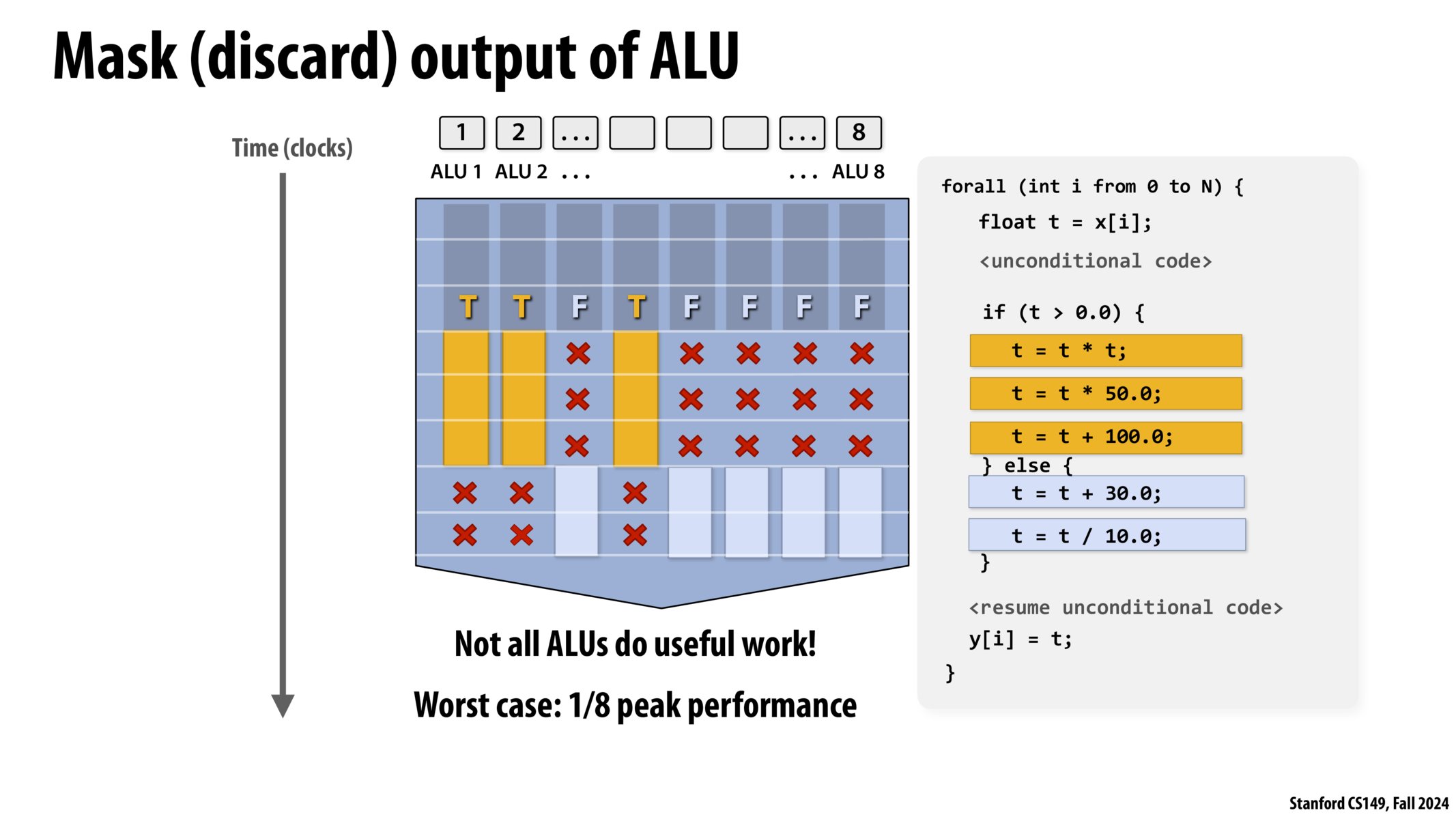
在现代向量运算器上,
比如 8 个单元的 ALU,
并不是每个单元都能有效利用
(每个单元都有自己的数据要处理,
有自己的条件判断分支)。
程序不可避免需要 if else 语句,
这就导致有的时候我们并不能充分发挥并行计算的全部性能
(也就是没做到“物尽其用”的硬件性能压榨)。
老师问:
有没有一种 if 语句,
能让并行化的性能反而降低为 1/8?
答案是:
if 里进行模 8 判断,
在 1/8 的情况下进入代码块 1,
在 7/8 的情况下进入代码块 2,
但代码块 1 所做的事情是代码块 2 的很多很多倍
(极端情况是代码块 1 执行所有计算,
代码块 2 不执行计算),
这样总体性能就约等于 1/8。
为了避免在大多数情况下进入低性能运算分支,
我们应当仔细考察运算过程,
写出“高并行化”的“高性能”代码。
现代多核处理器
3 种不同形式的并行执行
- 超标量(Superscalar):利用指令流中的 ILP。并行处理同一指令流中的不同指令(只用一个核心(core))。
- 在执行过程中,硬件自动发现并行性。(发现一小段程序中有几条指令可以并行执行)
- 单指令流多数据流(SIMD)(Single Instruction Multiple Data):一条指令控制多个 ALU(只用一个核心)。
- 高效处理数据并行工作负载:摊销对多个 ALU 的控制成本。
- 由编译器(显式 SIMD)或在运行时由硬件(隐式 SIMD)进行向量化
- 多核(Multi-core):使用多个处理核心
- 提供线程级并行:在每个核上同时执行完全不同的指令流
- 软件创建线程以向硬件公开并行性(例如,通过线程 API)
现代多核处理器
回顾一下第一章的简单处理器架构:
- Fetch / Decode: 取指令、解析指令
- ALU(Execution):算数运算单元(执行器)
- Execution Context:执行上下文
简单扩展一下,利用前面提到的三种并行化策略,
我们就可以得到:
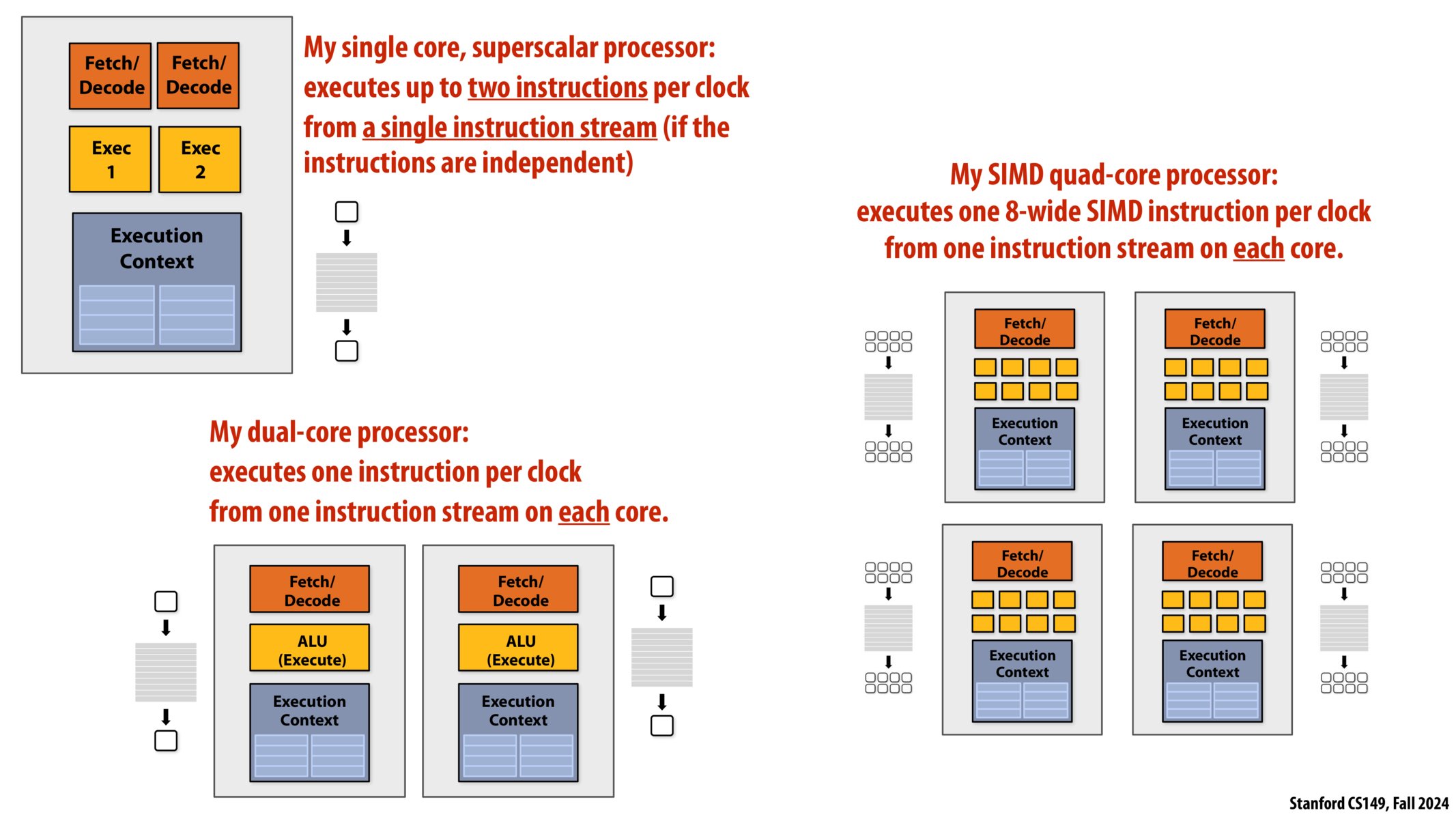
- 单核、超标量处理器:
- 2 个取指器/解析器
- 每个取指器对应 1 个执行器
- 多个执行器共用一个上下文
- 多核处理器:
- 就是多个核心复制粘贴(不考虑数据、缓存交流等)
- SIMD 四核处理器(八位宽):
- 4 个核心
- 每个核心 1 个取指器
- 每个核心 8 个 ALU(8-wide SIMD)
- 每个核心 1 个上下文
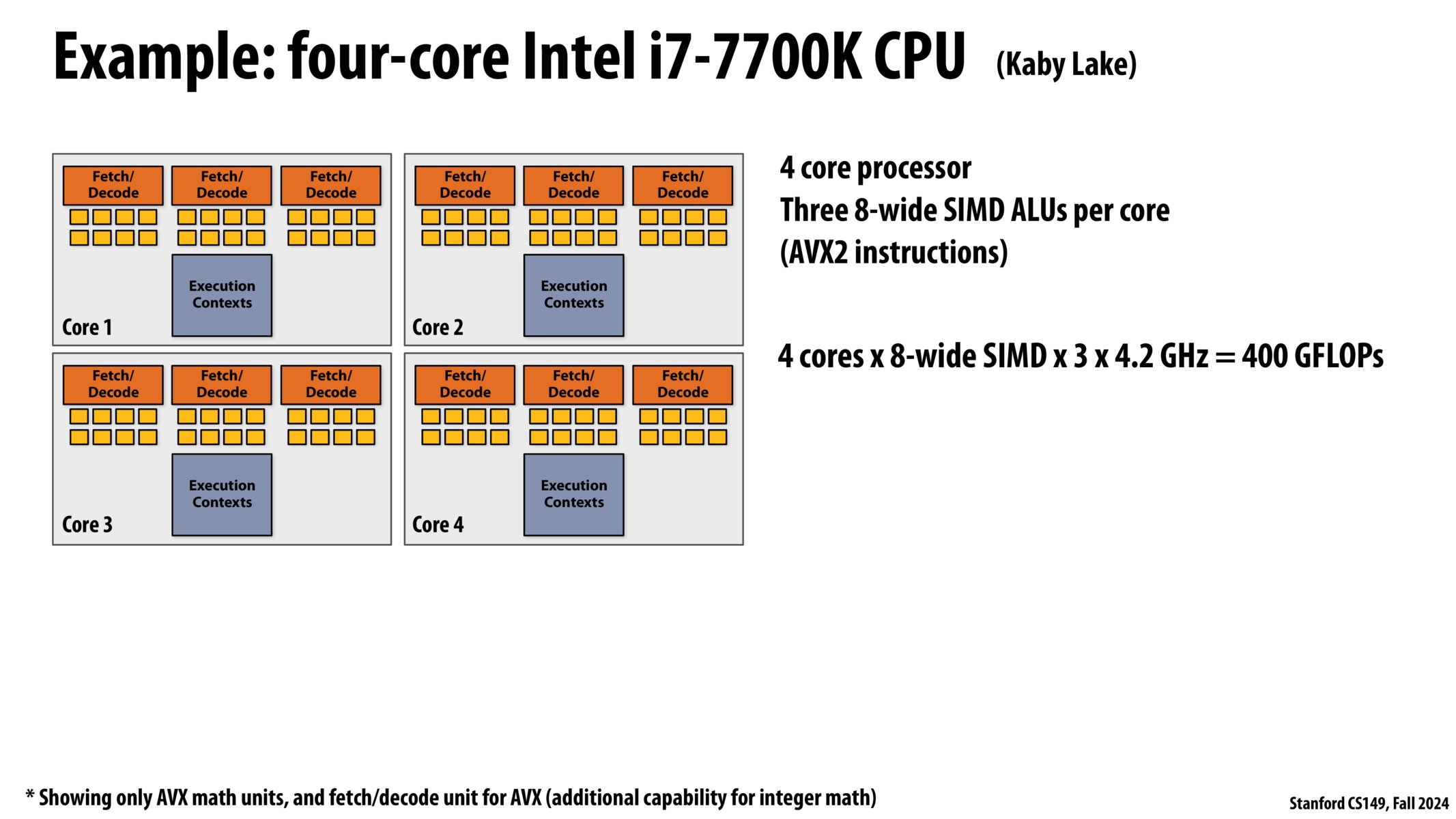
- 四核 Intel i7-7700k CPU:
- 4 核心
- 每个核心 1 个上下文
- 每个核心有 3 个 8 位宽 SIMD ALUs(AVX2 instructions)(每个核心 3 个取指器,每个取指器 8 个 ALU)
- 浮点运算性能:4(核) * 8(位宽)* 3(个)* 4.2Ghz = 400GFLOPs
- NVIDIA V100 GPU
- 80 个“SM(Streaming Multiprocessor)” 核心
- 128 个 SIMD ALUs 每”SM”(@1.6 GHz)=16 TFLOPs (~250 Watts)
第二部分:访问内存(Part2:accessing memory)
回想:非常长的数据访问延迟
延迟(在 4GHz 下的时钟周期数)
- L1 Cache:4
- L2 Cache:12
- L3 Cache:38
- DRAM:~248
回想:缓存未命中
- 冷启动未命中(Cold Miss / Compulsory Miss)
- 容量未命中(Capacity Miss)
- 冲突未命中(Conflict Miss / Collision Miss)
- 一致性未命中(Coherence Miss / Invalid Miss)
- 人为失效未命中(Manual Invalidation Miss)
回想:数据预取
当访问大量连续性可预测的数据,
比如访问一大块数组时,
可以很容易进行预测,
并进行数据预取(data prefetch)
但是,如果近期没有访问过数据,
也很难预测程序下一步要干嘛,怎么办?
第 3 种方法:用多线程隐藏停顿(hide stall)
就像可以边烧水边炒菜一样,
当我们知道某种操作耗时,
我们就先去处理别的事情。
等水烧开,再去关火。
多线程,就是复制我们之前提到的处理器架构中的“上下文”。
- 线程 1:计算,访问内存,计算。
- 线程 2:计算,访问内存,计算。
- 线程 3:计算,访问内存,计算。
- 线程 4:计算,访问内存,计算。
使用一个核心,我们可以创建 4 个线程,
按顺序执行这些线程。
当线程 1 访问内存、等待数据的时候
(前面提到的大约 250 个时钟周期),
让线程 2 进行计算操作,
当线程 2 访问内存、等待数据的时候,
让线程 3 进行计算…
由此,我们得到了大致的多线程执行时间流: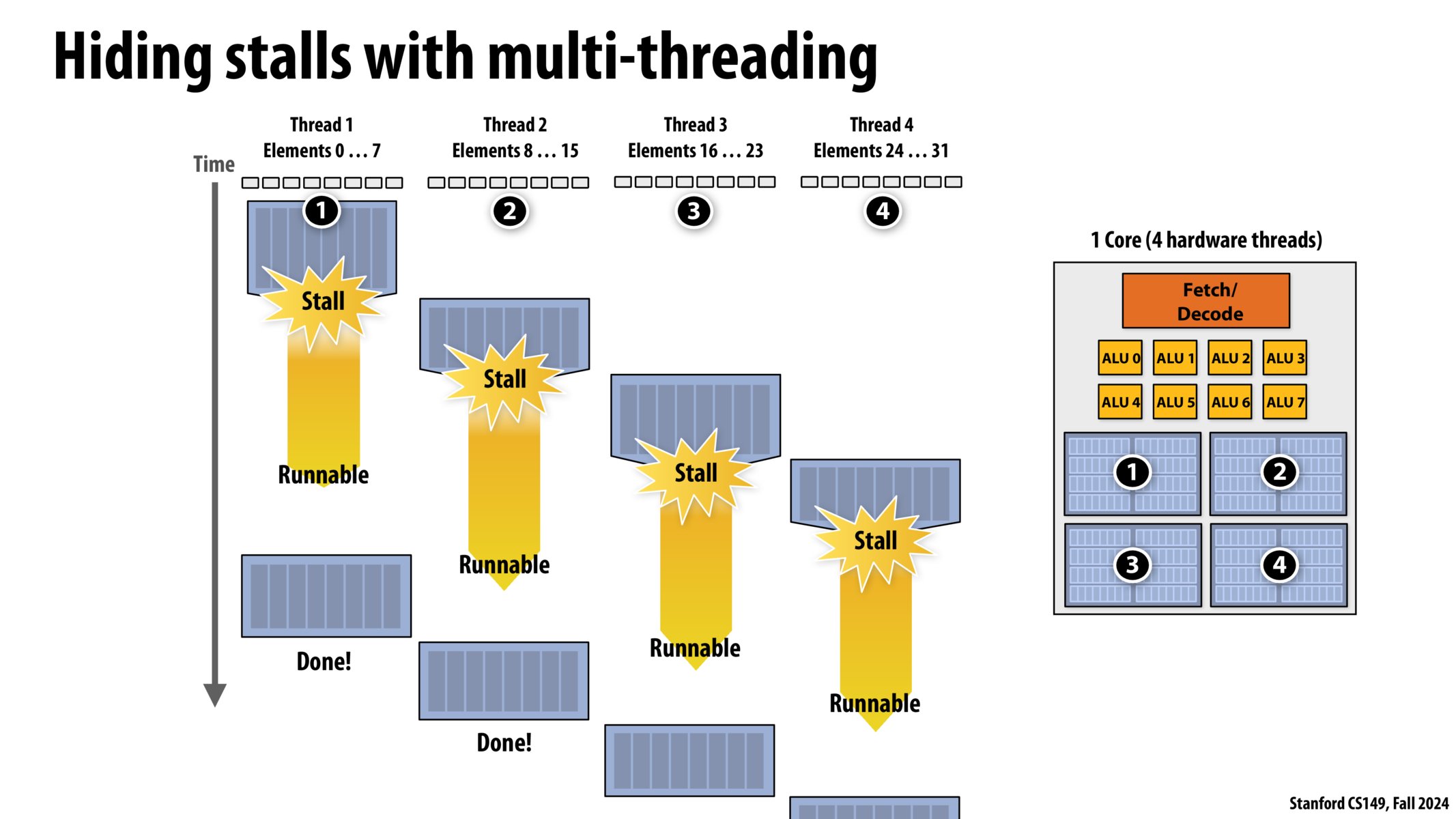
这个程序的 cpu 利用率为:100%
我们并没有减少停顿时间,
我们只是在停顿时间内去做别的工作。
等待,但不仅仅是等待
边等待,边计算
多线程,具体多少线程?
继续回想案例:计算一组 y[i]=sin(x[i])
假设:计算耗时 20%,传输数据耗时 80%。
假如只有一个线程,
那么 cpu 有 80% 的时间在 stall(停顿),
也就是等待内存读写(load/read memory)。
如果有 5 个线程,
那么在 1 个线程等待数据的 80%时间内,
剩下的 4 个线程可以完全占用 cpu,
当数据传输完毕,线程 1 回归计算操作,
cpu 利用率达到了 100%,
耗时缩短为原来的 20%,
从耗时结果上看,我们“隐藏了停顿”。
更多的线程不会带来更多的性能提升,
cpu 利用率已经到了 100%,
再增加线程反而会因为上下文切换,
导致耗时更多。
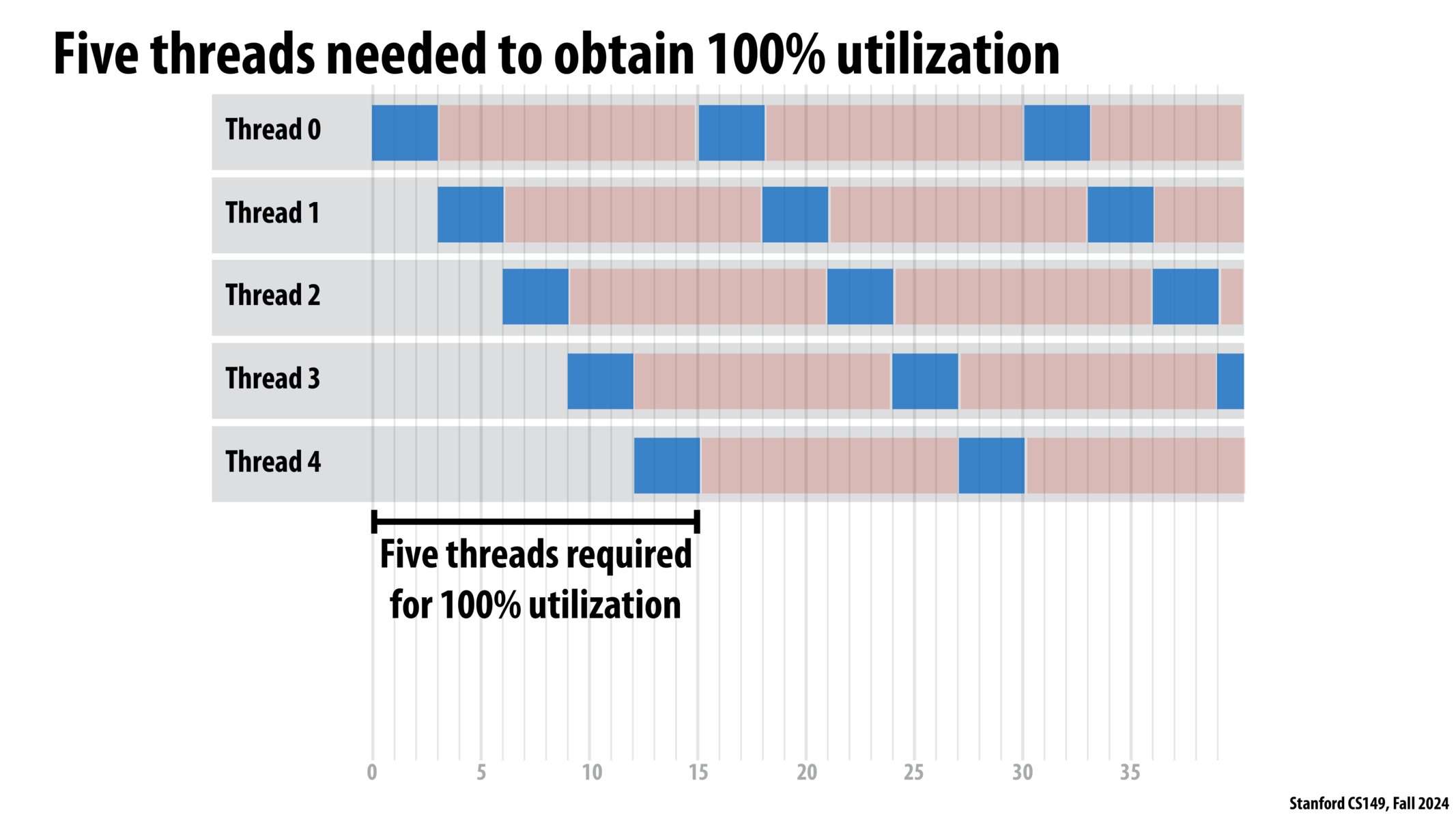
那么,当计算耗时占比为 x(x∈(0, 1))时,应该设置几个线程?
先想象一个线程在执行,
数据传输时间占比为:1-x
为了占满(cover)等待时间,我们需要几个额外的线程呢?
那当然是 (1-x)/x 个啦。
所以总线程数是:y = (1-x)/x + 1 = 1/x
结论:
当计算时间占比x,线程数应设置为ceil(1/x)。(ceil:向上取整)
硬件多线程
Hardware-supported multi-threading
硬件支持的多线程
- 硬件核心管理多个线程的执行上下文
- 核心仍然拥有相同数量的 ALU 资源:多线程只有助于更有效地使用这些资源,在面对内存访问等高延迟操作时
- 处理器决定每个时刻运行哪一个线程
- 交错多线程(也称时间多线程)
Interleaved multi-threading (a.k.a. temporal multi-threading)- 每个时钟,核心选择一个线程,并运行这个线程的一条指令,在核心的 ALUs 上
- 同步多线程
Simultaneous multi-threading (SMT)- 每个时钟,核心从多个线程中选择多条指令在 ALUs 上运行
- 示例:英特尔超线程(Hyper-threading)(每个内核 2 个线程)
你应该知道的一些术语
- 指令流 Instruction stream
- 多核处理器 Multi-core processor
- SIMD 执行 SIMD execution
- 一致控制流 Coherent control flow
- 硬件多线程 Hardware multi-threading
- 交错多线程 Interleaved multi-threading
- 同时多线程 Simultaneous multi-threading
回想:烹饪过程
当你需要等待一件事,那你就去做另一件事
多线程为什么能提高效率?
本质是通过 停顿时切换(switch on stall),
也就是在停顿时干别的事,
消除了停顿时间。
在停顿、等待时,切换任务,去干别的事情,
保证计算机资源充分利用,
“压榨硬件性能”、“物尽其用”。
现代处理器
例子:Kayvons 虚构的多核芯片
现在,我们假想有一个处理器,性能参数如下:
- 16 核心
- 8 SIMD ALUs 每核心(共 128)
- 4 线程 每核心(共 64 线程)(硬件多线程)
- 16 最大并行(simultaneous)指令流
- 64 最大并发(concurrent)指令流
- 那么需要创建 512 个任务(task),如果你要完全“隐藏”延迟
例子:Intel Skylake/Kaby Lake core
- Skylake 微架构(第六代 Intel Core)
- 发布时间:2015 年
- 制程工艺:采用 14nm 工艺。
- 支持 DDR4 内存:首次支持 DDR4 内存(同时兼容 DDR3L),大幅提升内存带宽。
- 微架构更新:
- 执行单元优化:增加了调度器和缓冲区大小,提升多线程性能。
- 分支预测增强:改进了分支预测算法,减少错误预测的开销。
- 更深的流水线:更高的指令并行性,使得单核性能(IPC)显著提升。
- 三级缓存改进:更高效的共享缓存,提高多核间的数据访问速度。
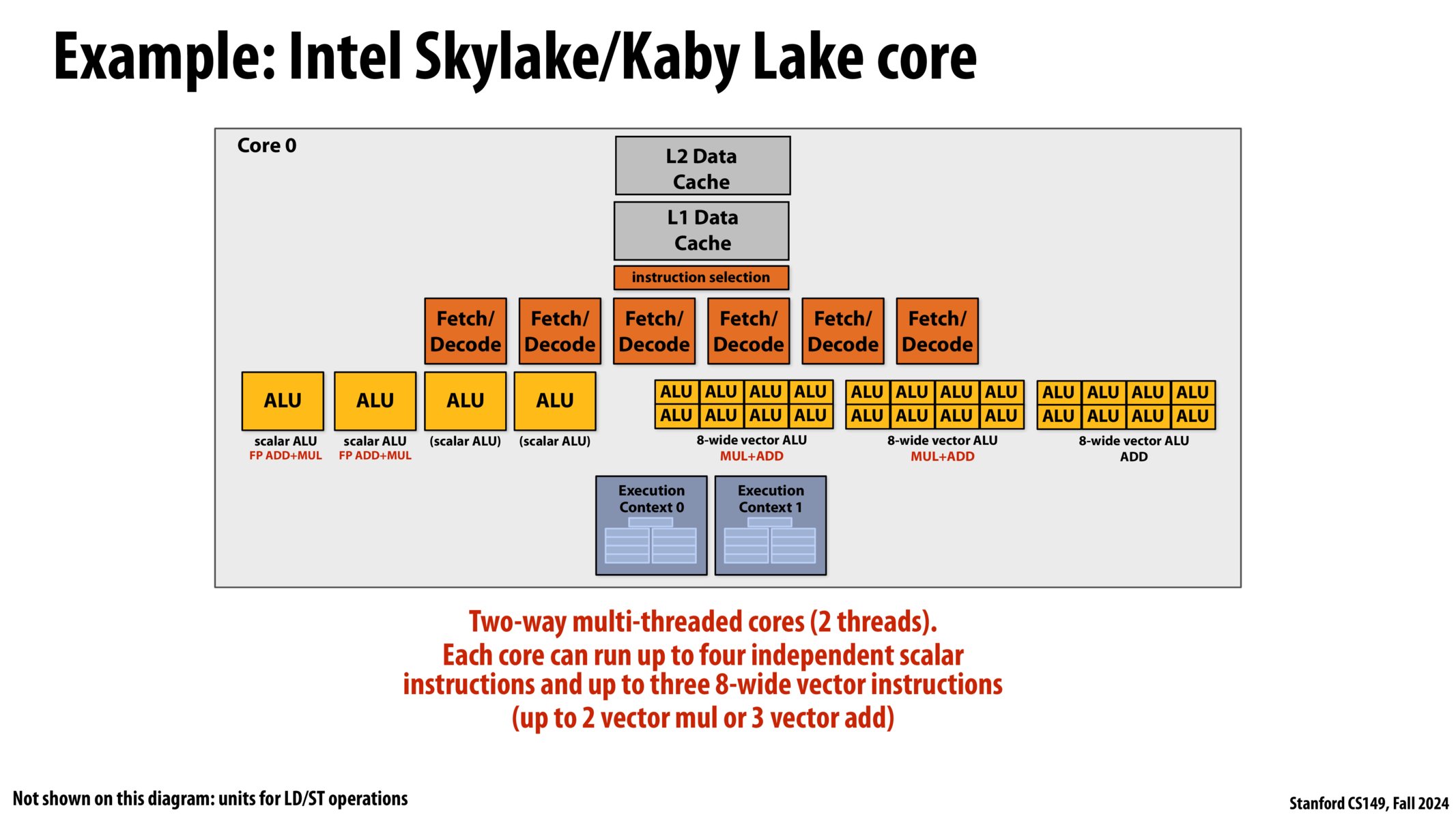
这张图是 Intel Skylake/Kaby Lake 架构 CPU 的其中一个核心 Core 0.
双路多线程核心(2 线程)。
每个核心最多可以同时运行 4 个独立的标量指令和 3 个 8 宽的向量指令
(最多 2 个向量相乘或 3 个向量相加)
学生:双线程可以同时运行?但我们仍然需要按顺序取指令?额外的取指器/解码器是如何起作用的?
老师(Kayvon):宽松地讲,可以想象这群取值器/解码器看作一个高级的取值和解码单元(”fancy fetch and decode unit”),它们有能力把“一堆指令”塞满“一堆执行单元(a bunch of execution units)”,取指器/解码器的操作是,从 Thread0 中找一些指令,在 Thread1 中找到一些指令,然后我有很多黄框框(ALUs)需要被填满,我要做的就是尽可能地用指令填满这些黄框框,来充分利用 CPU 的计算性能(ALUs)。
“every thing here composes”,
在这个芯片上,一切都组合在了一起
这个芯片是一个:
- 超标量芯片(Superscalar)
- SIMD 芯片
- 硬件同时多线程芯片(Intel 超线程)
- 多核芯片
我的补充:
- 然而有的指令是标量,有的是向量,有的指令有依赖关系,有的指令可以并行执行但间隔太远,它们并不一定能并行,这取决于程序。
- 程序(指令流)并不会按顺序执行,因为很可能你写的程序编译后,可并行性差得要命!因此,现代处理器会乱序执行。
- 早期超线程技术中,会有缓存问题。比如线程 1 修改了线程 2 的缓存,导致缓存失效需要重新读取。有时,减少线程数会有利于应用程序更好地运行。
- 即使是目前,超线程技术仍存在安全问题。因此,一些安全专家建议全面禁止超线程。
例子:NVIDIA V100 GPU
- 共 80 个“SM(Streaming Multiprocessor)” 核心
- 每个 SM 有 64 个 warp 执行上下文
- SIMD ALUs 位宽为 16,启动 2 个时钟周期后为 32
64 \* 32 = 2048最大数据并发量/SM
80 \* 2048 = 163840 最大数据并发量(每个时钟周期)
(另注:不是并行,并行量略低)
[!NOTE]
并行计算性能为:
FP32 性能 = CUDA 核心数 × 时钟频率 × 每个核心每周期的运算FP32 性能 =
5120 × 1.53GHz × 2 = 15.7 TFLOPS= 15.7 * 10^12 FLOPS大约每秒 16 万亿次 32 位浮点运算
仅在硬件级别,就提供了 16 万的并发量。
这还没有考虑,
实际任务的计算耗时与数据传输耗时占比,
为了完全覆盖停顿时间,
所需要的额外线程数。
如果仍然使用计算 sinx 的任务来占满这个芯片,
除非你有成千上万的数据要处理,
否则还是别费劲了。
这就是为什么一个小型 DNN 在大型 GPU 上运行不佳。
因为我们没有足够多的任务去塞满它
如何高效利用现代处理器?
为了高效地利用现代并行处理器,必须:
- 有足够多的并行工作来利用所有可用的执行单元
(跨多个核心和每个核心的多个执行单元) - 并行工作任务组必须要求相同的指令顺序
(利用 SIMD 执行) - (软件要向硬件)暴露比处理器 ALUs 数更多的并行工作数目,来保证并发能够隐藏内存停滞。
多线程的另一个作用:塞满计算单元
继续设想一个处理器,
他的 ALUs 支持 4 个标量指令和 3 个向量指令。
假如单线程运行,
硬件最多只能发现 2 个标量可以并行
(或者 2 个向量指令,
或者 1 个标量 1 个向量),
因为其他指令有依赖关系或者相距过远无法并行。
当双线程运行,
硬件可能就会在 thread0 找到 2 个标量指令,
在 thread1 找到 2 个向量指令,
然后同时运行它们。
当线程数来到 4 个,
处理器很聪明的找到了 4 个标量指令和 3 个向量指令,
然后把它们塞满 ALUs,
这样,这个虚构处理器就达到了最高的利用率。
我们就知道了乱序执行(指令重排)的好处之一:
原本由于相距过远无法并行的指令,
打乱顺序后紧挨在了一起,
就可以并行了
(在没有依赖关系的条件下)。
那如果有依赖关系呢?
- 内存屏障:处理器会通过内存屏障(读、写、全屏障)等技术确保逻辑无误。
- 寄存器重命名:通过寄存器重命名技术,处理器可以消除伪依赖关系,从而提高并行度。
[挖坑]
Kayvon 老师:但是 AMD 和 NVIDIA 的 GPU 工作方式略有不同
GPU SIMT(Single Instruction Multiple Thread)
大部分现代 GPU 永远都只会编译生成
标量指令(scalar instruction)
GPU 核会检测硬件线程的执行指令是否相同
(通过判断程序计数器(pc)),
如果相同,就用一个向量指令来代替原本的多个相同的标量指令。
假设一个 GPU 核心有一个 8 位宽的向量 ALUs
(可以同时计算八个操作)。
假设有 8 个线程,
每当这 8 个线程的程序计数器(pc)相同,
那么就在这 8 位宽的向量运算器上同时运行这 8 个指令
这与编译了一个 8 位宽 SIMD 向量操作效果相同。
那么如果有 7 个线程的 pc 相同,仅有一个线程不同呢?
那个线程会被 “masked off”(屏蔽)。(回想:第二讲中的条件分支)
思考题
你写了一个 C 语言应用程序,生成了 2 个线程
你的应用程序运行在如下处理器上:
2 个核心,每个核心 2 个执行上下文,每个时钟最多执行 ( ) 条指令,一条指令是 8 宽的 SIMD 指令。
问题 1:谁负责将应用程序的线程映射到处理器的线程执行上下文?
- 答:操作系统(Operating system)
问题 2:如果你来实现一个操作系统,那么如何将这 2 个线程分配给 4 个执行上下文?
问题 3:如果您的 C 程序派生了 5 个线程,如何分配给执行上下文?
- 如果是两个截然不同的线程,把他们都分配到一个核上显然是不太合适的
- 那如果这俩线程需要访问相同的数据呢?想要共享缓存或者其他资源呢?答案可能恰恰相反
学生:现在我们有多个执行上下文,那么如何决定是使用硬件多线程还是使用超标量架构?
Kayvon:这是芯片(chip)实现的细节,不是操作系统的任务。
操作系统会说:“hey,chip!请你给我在 core1 上运行 thread3。”
芯片会在每个时钟周期,根据自己拥有的执行上下文,决定执行哪些指令,如何执行,这个决策每秒数亿次,都发生在硬件中。
操作系统还可能这样说:“你要 8 个线程来塞满你对吧。好,这是我从 1000 个准备好的用户线程中挑选的 8 个,你先给我执行一下子。”
这就是操作系统级别的上下文切换。
这种操作大约耗时十万个 cycles(时钟周期),
且发生频率很低。
学生:有没有办法让编译器强制执行一些行为?
Kayvon:是的。现代操作系统有 APIs,可以指定一个线程在特定的执行上下文中运行。
学生追问:哦不,只是强制执行超标量架构的与否。比如说我就是不想乱序执行,不想让多个运算器协作
Kayvon:据我所知,这不是你可以过多干预的事。
当然,你可以说你想关闭超线程这一功能,这很简单。
如果你要干预处理器调度细节,据我所知,我并不清楚你有多少控制权。
也许在 BIOS 级别可以,但在标准 OS 中可能不行。
其三:Multi-Core Architecture Part II + ISPC Programming Abstractions
第三章:多核架构第二部分(延迟/带宽 问题) + ISPC 编程概述
摘要:完成多线程和延迟与带宽。ISPC 编程、抽象与实现
思考题:C[i] = A[i] * B[i]
假如有两个非常长的数组,成千上万。
那么,它们之间的加法或者乘法计算,
并将结果存入 C 数组中,
这个计算是否适合在现代的面向吞吐量的并行处理器上执行?
你会觉得这个向量运算太适合在现代处理器上执行了,
现代处理器不就是向量优化的嘛?
但实际上,这可能是一个最糟糕的程序,
在现代处理器上,
然后你每天都会运行它。
为什么?
想象一下,这些数据存放在哪里?
硬盘上。
- 最新的闪存固态硬盘,传输速率也不超过 64GB 每秒(PCIe 5.0)
- Nvidia V100 的计算性能大致为 16 万亿次浮点运算每秒。
假如我们正好需要算 16 万亿个浮点运算。
也就是说,我们有 2\*16 = 32 万亿个数字存放在硬盘上,
需要花费大量时间(4*16TB / 64GBps = 8ks = 2.3小时)搬运到我们的 V100 上,
然后 V100 花了一秒就算完了,
接着我们又要花 2 个小时把数据搬回去。
是什么限制了并行计算效率?
带宽。
带宽 Bandwidth
101 公路
假设 101 号公路连接着旧金山和斯坦福,
- 为了简便运算,全长约为 50 km。
- 假设我们都以 100 km/h 的速度行驶。
问题 1:通行(延迟(Latency))时间是多少?
答:半个小时
为了保证安全,比如防止追尾,我们添加一条新的规则(初版):
- 只允许一辆车占用这条公路.
问题 2:那么每小时吞吐量为?
答:每小时 2 辆车。
那么如何优化吞吐量呢?
- 方法 1:开快点。
- 如果提速到 200km/h,就可以每小时通行 4 辆车!
- 方法 2:多建车道(lanes)。
- 把 101 公路增加到 4 车道,每小时就能通行 8 辆车!
- 方法 3:修改规则,允许同一车道开多辆车。
- 允许车间隔至少 1km,同时占用同一车道,既保证了安全,又增加了吞吐量。现在,每小时可以通行 100 辆车!
内存带宽
内存带宽是一个速率 – 单位时间内完成多少事情。
Memory bandwidth is a rate
– how many things are completed per unit time.
假设我现在有一个内存到处理器的带宽例子:
原始的:
- 假设我每秒发射 4 个方块
- 那么现在带宽就是:4 items/sec
带宽增加的:
- 我可以通过一次发射 2 个项目来增大带宽
- 现在带宽来到了:
2 * 4 = 8items/sec
我们会发现,带宽和延迟成为了不同的两个概念。
我们会在之后多次提到 流水线 这个词,
就像在 101 公路上多车道塞满车运行一样,
吞吐量 或者说 带宽 是可以远远超出 延迟 的限制的
带宽 != 延迟
例子:洗衣服
操作:洗衣服
- 洗(洗衣机) 45 min
- 烘干(烘干机) 60 min
- 折叠(大学生) 15 min
在这个例子中,洗衣服的 延迟 是 2 小时,
但吞吐量是多少呢?
如果我们只洗 2kg 衣服(假设洗衣机容量是 2kg 衣服),
那吞吐量就是每 1 kg/h。
如果我们有 4kg 衣服要洗呢?
你可以再买一套洗衣机+烘干机,
再叫上你的好伙计,
然后并行进行两堆衣服的洗烘叠三步骤。
最后骄傲地说:“嘿,瞧,我们把效率提高到了 2 倍!”
我想,傻子都不会这么做。
假如有很多堆衣服要洗,正常人都会这样做:
在第一堆衣服洗完烘干后,
把第二堆衣服(在洗衣机里洗好的)送进烘干机,
把第三堆衣服送进洗衣机洗。
因为,我们始终都想要填满 流水线 上的每一个单元。
所以,我们不希望 cpu 闲置,ALUs 闲置,或者很多线程在等待执行。当然,我们也不希望洗衣机或烘干机在洗一堆衣服时处于闲置状态。
那么,流水线工作的洗衣机和烘干机,
整体系统的吞吐量(Throughput)是多少呢?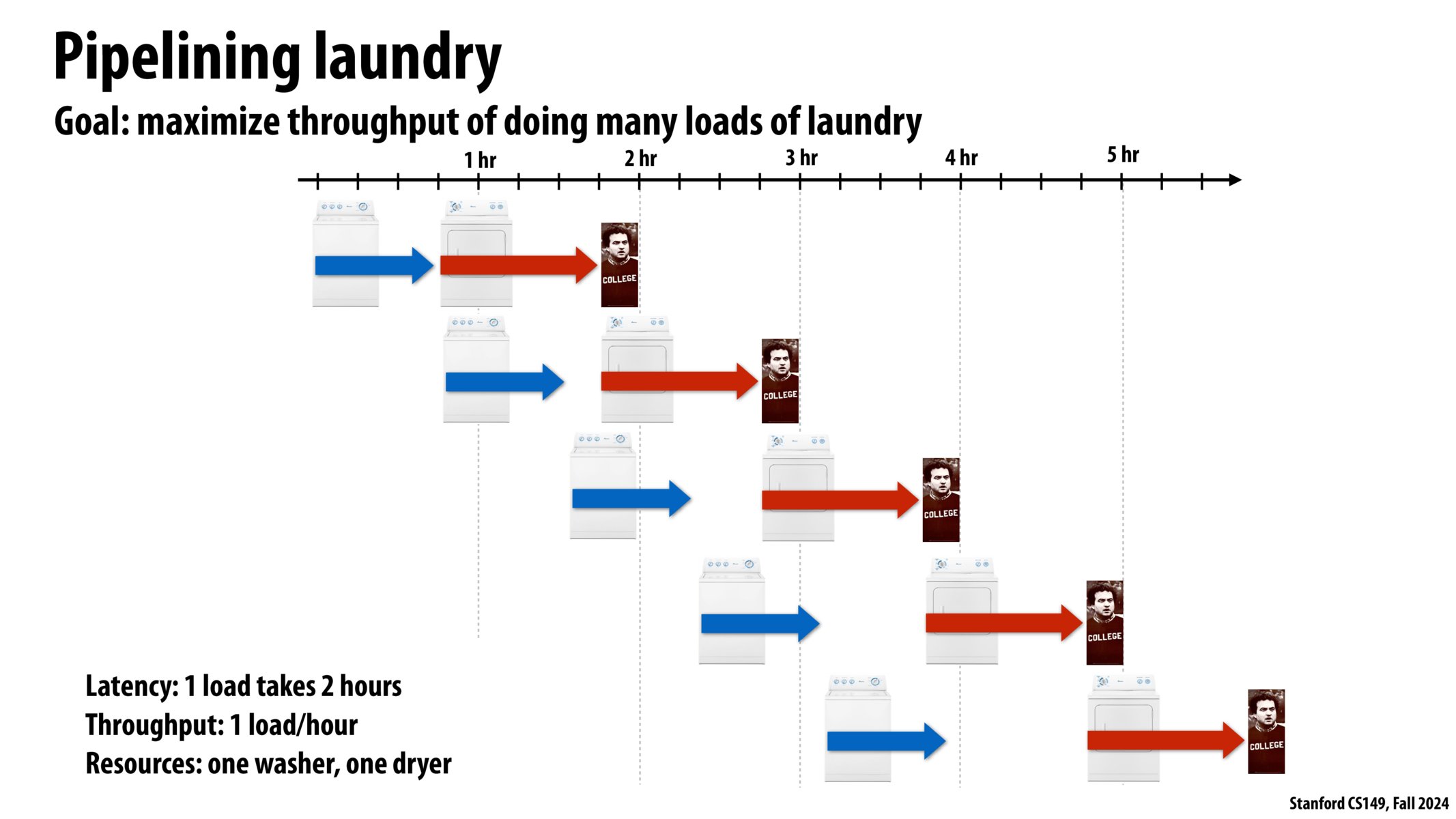
可以看到,烘干机一直在拖后腿,
洗衣机早就洗好了,
他们的差距越来越大,
系统吞吐量不会超过 1 load/hour,
这也正是烘干机的工作时间 – 1 hour。
短板效应
流水线中最慢的单元限制最大吞吐量
试想一下,如果计算机各个单元也这样不匹配,
数据就会像衣服一样,
逐渐“堆满”有限的缓冲区(烘干机的机体上/计算机的缓冲区),
直到挤爆缓冲区,把电脑卡死,
这是非常荒谬的。
回想计组中的指令流水线:取指、译码、加减乘除、读取、写回。
在计算机组成中,我们的做法是:更多的洗衣机,更少的烘干机
(更多的 ALUs,更少的取指器)
这个例子中,洗衣机和烘干机的速度比例是 1/45 : 1/60 = 4:3 ,
所以我们最好用速度的反比 3:4 的比例来配置洗衣机和烘干机的数量,以防止衣服堆积在中间。
回想:案例:C[i] = A[i] * B[i]
现在,让我们回到计算机的视角:
处理器很快,
但内存带宽限制了系统的吞吐量。
内存带宽就像那个烘干机,一直拖后腿。
最先进的 NVlink 传输速率是 900GB/s。
假如在 V100 上运行这个程序,
每个数学运算都需要 12 个字节(3 个 4 字节的浮点数),
V100 的每秒浮点运算次数约为 16 万亿次,
每秒钟,我们需要大约 100TB 的数据,
但最先进的 NVlink 技术也只能达到 900GB/s 的传输速率。
可以理解为:你的洗衣机比烘干机块一百倍。
所以,这个程序在 V100 上运行的效率是 **小于 1%**。
此时,缓存没有用,缓存只在重复读取时有用。
如果你只是想做这样的一次性简单向量运算,那么面对 1% 的超低效率,你无能为力。
除了改变你的程序,或者等待更快的内存系统出现,你别无选择。
这个程序是 带宽限制 的(bandwidth limited)。
那能不能增加“车道(lanes)”呢?
很遗憾,就像现实中都很少有 8 车道一样,专家们也受到物理上的限制和系统总线的限制,64 位地址已经相当复杂,再加车道可能难以与其他部件协调。NVlink 已经很快了,但造价昂贵,得不偿失,只是跟处理器比起来,内存带宽确实相对太慢了。计算机是一个整体系统,整体大于局部之和。
学生:既然如此,V100 为什么要造出一百倍的计算单元来?
Kayvon:因为大部分深度学习并不是简单的一次性向量运算,而是 读取一次,计算多次。
ISPC
ISPC 全称是 Intel SPMD Program Compiler,它是由 Intel 开发的一种编程工具,用于编写单指令多数据(SPMD,Single Program Multiple Data) 风格的并行程序。它特别适合在现代 CPU 和 GPU 上运行高性能并行计算任务。
这是一种相当冷门的语言,
冷门到你在 Github 和 Stack Overflow 上找不到几个相关东西。
使用它的人数可能就是本课程的学习人数乘以开课年限,再加上几百个英特尔相关方向的从业者。
- ISPC:Intel SPMD Program Compiler
- SPMD:Single Program Multiple Data 单程序多数据
- https://ispc.github.io/
- https://github.com/ispc/ispc
- https://pharr.org/matt/blog/2018/04/30/ispc-all
为什么 C++ 不够快?为什么要设计 ISPC?
ISPC 重写 sinx()
回想:一般的 sinx()
1 | |
它的主函数可能是
1 | |
现在,看看如何用 ISPC 重写这个程序
当调用 ispc_sinx()函数时,
它并不像常规 C 语言程序一样(调用-返回),
它的大致流程是:
- 调用 ISPC 函数,生成一群
程序实例(program instances)(不是线程 thread)- 程序实例的个数由
programCount(程序计数)决定 - 每个程序实例的
programIndex(程序索引)是不同的,以此来区分不同程序实例的任务
- 程序实例的个数由
- 所有实例同时运行 ISPC 代码
- 每个实例都有自己的局部变量副本
(代码中的蓝色变量,稍后我们将讨论“uniform”) - 返回时,所有实例都完事了
问题:假如
programCount(程序计数)为 8,也就是 8 个程序同时运行,编号为 0 到 7。那么请问,每个程序(比如程序编号为 j 的程序),做哪些元素的运算?答:编号为 j 的程序,做
sin(x[i]),其中i mod j = 0
想象一下希尔排序,就是不断变换步长进行插入排序,
其中每一轮插入排序做的工作,
就是现在这个 ispc 派生的 8 个程序实例所做的工作。
它们在空间上(数组上)是 交错执行 的。
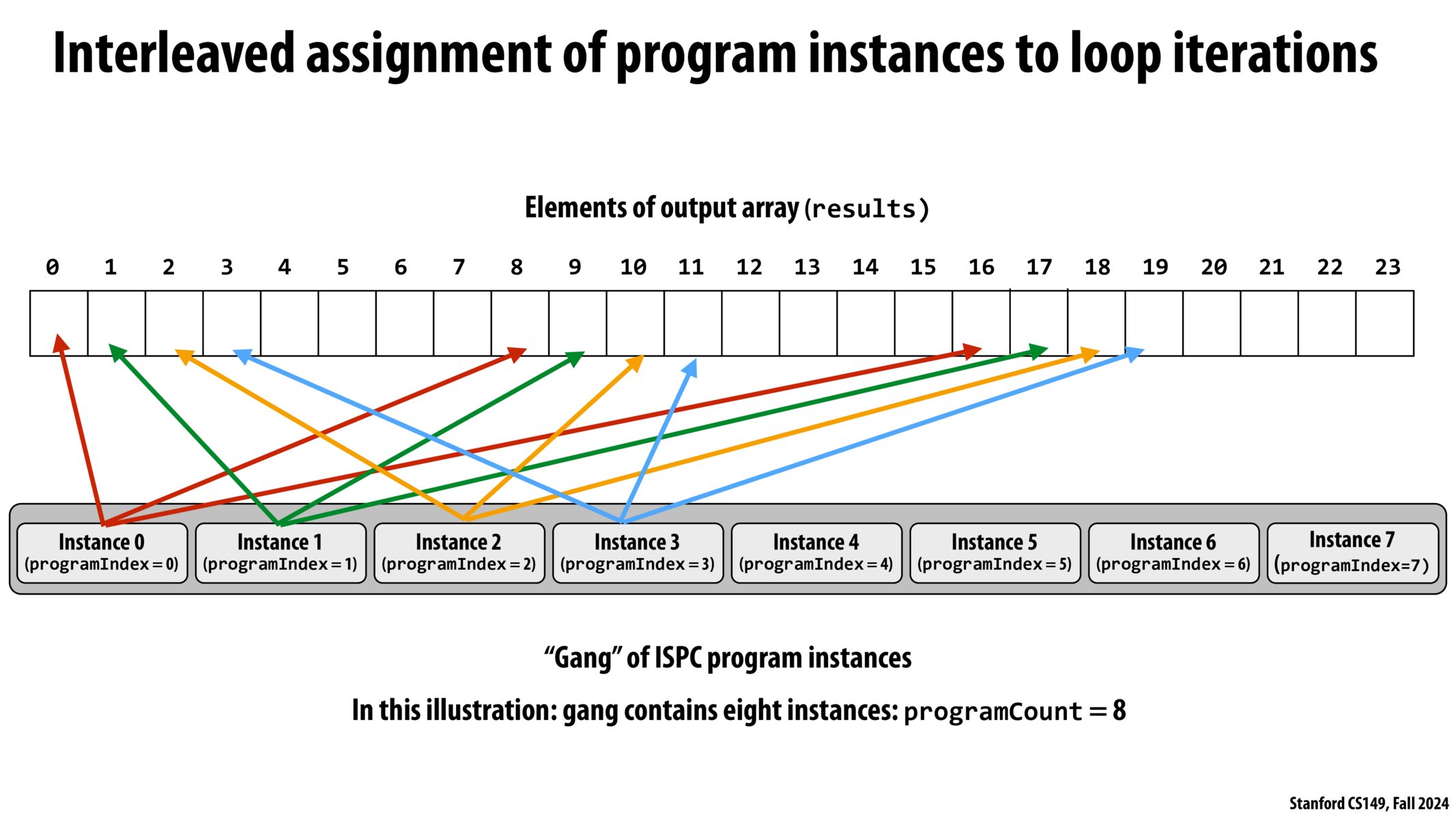
另一种方式则是分块执行


我们有多种方式实现 SPMD,
但如何分配这些派生的 Program Instance,
是最好的方式呢?
因为 Program Instance 只是 Intel 提出的一个概念罢了,
具体到硬件还是要线程来干。
分配程序实例的 4 种方式:
Kayvon:I don’t care.
是的,这四种方式都是 foreach 的正确有效实现,
但具体怎么实现?
我不关心。
有可能这个任务更适合分块处理,
那个任务更适合交错处理,
甚至有任务适合单线程处理。
总之,全部交给编译器和硬件决定。
这就是foreach。
我们不需要关心 foreach 具体实现的细节,
我们只需要 foreach 循环迭代一个东西,
剩下的,交给编译器和硬件。
1 | |
Kayvon:我们讲了很多概念,也有很多概念性问题被学生提出,这很正常。因为实际情况更加复杂,就像实际硬件会结合超标量、SIMD、多核与硬件多线程等技术一样,ISPC 的
Program Instance(程序实例)究竟是如何实现的,我们也不必过多关心,或许是自动多线程,或许是自动向量化(向量指令代替标量指令)。或许随着 ISPC 的编译器迭代更新和计算机其他领域的技术突破,未来实现程序实例的最优底层方式和细节会有所变化,但无所谓,我们的代码是不变的。这种层次结构设计非常非常重要(very very important),在良好的编程系统设计中:既提供高级语法
foreach,也提供自定义实现循环迭代的语法(四种方法)。
在大多数情况下,foreach都会表现得很好,但如果你对自己的程序和机器(软件和硬件)相当了解,想要自定义迭代策略(do it yourself),也完全 ok。
相互独立的迭代?
1 | |
这是一个有效的 ispc 程序吗?
不是。
当你使用 foreach,
代表你默认这些迭代是相互独立的,
可以按照任意顺序执行,
而不会影响最终结果。
但事实上呢?
这些迭代的顺序会影响最终的结果,
结果是不可预知的。
因此,无法乱序执行的迭代不能交给 ispc 编译器自行优化。
这就是竞态条件(race condition)
竞态条件(race condition)是指在并发程序中,多个线程或进程对共享资源进行访问和修改时,结果的正确性依赖于访问的顺序。如果不同线程的执行顺序不一致,就可能导致程序的行为不可预测,产生错误结果。
uniform:返回值必须是公共的
uniform 关键字:代表所有的 程序实例(Program Instance)
错误的程序 1
1 | |
这个程序无法通过编译,
具体而言,无法通过编译器类型检查。
因为 sum 没有被 uniform 修饰,
每个 程序实例 持有不同的 sum,
没有办法返回一个统一值。
错误的程序 2
那如果加上 uniform 修饰呢?
这个程序仍然不会正确运行。
它会遇到另一个竞态条件。
1 | |
正确的程序
1 | |
reduce_add() 函如其名,就是做累加的。
跟 python 中的 reduce() 一样,只不过它是跨程序实例的。
这样就得到了正确的并行累加方法,避免了竞态条件。
案例:三个程序
操作系统一般通过软/硬件计时器,
来周期性地处理各个进程、线程的上下文切换,
比如说我的电脑有 8 个硬件线程,
在某一时刻,计时器 a 到点了,
操作系统就会对硬件说:嘿,硬件,这 8 个线程你去运行吧!
在另一时刻,计时器 b 到点了,
操作系统经过一些处理和判断后,
挑选出新的 8 个线程,继续交给硬件执行。
Kayvon:既然你(学生)问了,那我正好有一个 C 语言测试程序(去除了所有编译器优化)。
- **
do_work()**:基准工作函数,空函数,仅用于测试调用开销。 - Test 0(单线程):在单个线程中调用
do_work()N 次。 - Test 1(大量线程创建与销毁):为每次
do_work()调用创建一个新线程,调用后立即销毁,总共 N 次。 - Test 2(线程池):创建 8 个线程的线程池,共同完成 N 次
do_work()调用。 - 其中,N 大约是十亿.
结果
- Test 0(单线程):0.001667 s
- Test 1(创建大量线程):13.15 s
- Test 2(线程池):0.04 s
分析
Test 1 最慢(13.15s):
- 频繁创建和销毁线程,涉及大量系统调用和调度开销。
- 线程的创建和销毁在操作系统层面涉及 内核上下文切换,开销非常大(数十万 CPU 周期)。
Test 2(线程池)比 Test 1 快 333 倍:
- 线程池 复用 线程,避免了频繁的创建和销毁。
- 线程调度仍然存在,但远低于 Test 1。
Test 0(单线程)比 Test 2 还要快 23.7 倍:
- Test 2 仍然涉及 线程调度,而 Test 0 只是在 同一个线程中执行循环,完全避免了线程切换的开销。
- 用户态函数调用 比 线程切换 快得多。
Kayvon:不要混淆你在操作系统中学到的知识。
操作系统的上下文切换一般需要数十万周期,
硬件多线程的上下文切换只需要1个周期,
它们非常不同!
如果你要用操作系统的上下文切换来隐藏内存访问的延迟,
内存访问会在几百个周期内完成,
但你仍然需要等待数十万个周期来切换线程上下文。
这毫无意义!
所以:概念是相同的,但数量级完全不同。
其四:Parallel Programming Basics
第四讲:并行编程基础
摘要:构建并行程序。在数据并行和共享地址空间模型中并行化程序的过程
主题:编写优化并行程序的案例研究
Amdahl’s law
加速比计算公式:Sn = (Ws + Wp) / (Ws + Wp/p)
其中,Ws 表示无法被并行化的部分,Wp 表示该部分可以用 p 个节点进行并行计算。
当 p 趋于无穷大时,Wp/p 趋于无穷小,
该式简化为:(Ws + Wp) / Ws = W / Ws。
其中,W = Ws + Wp。
- 设并行部分占比
a = (Wp / W) ∈ [0, 1] - 则串行部分占比
Ws / W = (W - Wp) / W = 1 - a - 则加速比
Sn = 1 / (1 - a + a/p) - 则当
p -> ∞时,Sn = 1 / (1 - a)
案例:图像处理
假如我有两个图片,尺寸都是 N x N。
我要做一些图像处理,比如计算所有像素的和。
时间复杂度显然是 N^2。
假如我的机器有 p 个并行处理器
(可能是向量、硬件多线程等方式实现的,不作详细讨论)
策略 1:
- 并行处理第一个图片
- 时间:N^2/P
- 串行处理第二个图片
- 时间:N^2
于是我们很容易得到加速比:
Speedup <= 2n^2 / (n^2 / p + n^2)Speedup <= 2
策略 2:两个图片都并行处理,最后把部分和总起来。
- 并行处理第一个图片
- 时间:N^2/P
- 并行处理第二个图片
- 时间:N^2/P + p
加速比:
Speedup <= 2n^2 / (2n^2 / p + p)- 当
N>>P时,Speedup -> p
Amdahl’s law
如果用 s 表示程序中无法并行化部分的占比,
在 p 个处理器上的最大加速比为:
speedup <= 1 / (s + (1-s)/p )
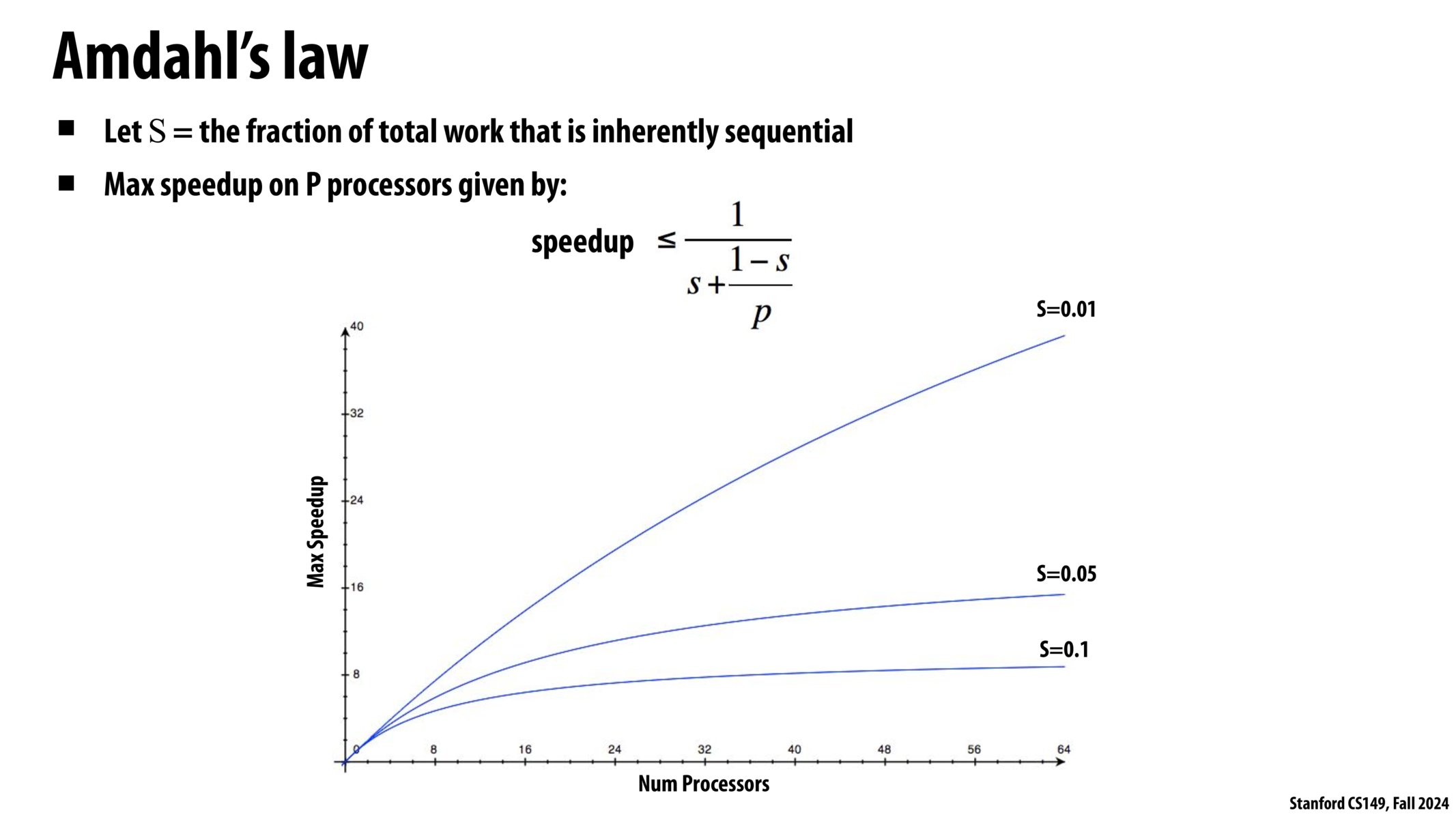
假设你的程序只有 1%是串行的,
另外的 99%能够在 64 核心机器上得到完美优化,
最大的加速比也只有四十倍。
那 1% 的串行部分真的开始拖后腿了。
如果我的程序有 10% 无法并行化,
我在 64 核心机器上的最大加速比大约是 8 倍。
现在,如果用一个含有 1.5 亿并行单元的超级计算机上运行你的程序,
那你最好把串行部分缩减到 0.00000001%,
否则,你可能还不如不用这台计算机。
幸运的是,我们运行的大多数代码都相当容易并行化。
所以,就像我说的,在这个课上,
理解如何分解问题几乎就像我们在这里做的一样,
取决于你编写一个能很好的分解问题的程序。
Don’t hope for magic here.
并行程序(分解-分配-编排-映射)

创建一个并行程序并运行,这个世界发生了什么?
四个步骤:
- 分解 Decompositon
- 子问题:高维度的任务分解(tasks)
- 承担者:程序员(Programmer)
- 分配 Assignment
- 并行线程(workers)
- 承担者:编译器/运行时(Compiler/Runtime)
- 编排 Orchestration
- 并行程序(通信线程)
- 映射 Mapping
- 运行在并行机器上
这些责任可能由程序员、系统(编译器、运行时、硬件)或两者都承担!
很多时候,我们更想让系统来帮我们完成这些任务,
我们不想在优化并行运算上浪费太多时间,
我们只想解决实际问题。
但有时候,你不得不自己承担这些任务
(比如让程序在你有生之年能够运行完)。
分解 Decomposition
- 谁负责将程序分解为独立的任务?
- 在大多数情况下:程序员
- 顺序程序的自动分解仍然是一个具有挑战性的研究问题(在一般情况下非常困难)
- 编译器必须分析程序,确定依赖关系
- 如果依赖关系依赖于数据(编译时未知)怎么办?
- 研究人员在简单的循环嵌套上取得了适度的成功
- 用于复杂通用代码的“魔法并行编译器”尚未实现
Assignment 分配
Assigning tasks to workers
将任务分配给工人- 把“任务”看作是要做的事情
- 什么是“工人”?(可能是线程(threads)、程序实例(program instances)、向量通道(vector lanes)等)
目标:实现良好的工作负载平衡,减少通信成本
可以静态执行(在应用程序运行之前),也可以在程序执行时动态执行。
尽管程序员通常负责分解(decomposition),但许多
语言/运行时负责分配(assignment)。
ISPC 任务动态分配
ISPC 运行时(对程序员不可见)
分配任务给线程池中的工作线程。
线程任务分配的实现:
在完成当前任务后,工作线程检查任务列表并把下一个未完成的任务分配给自己。
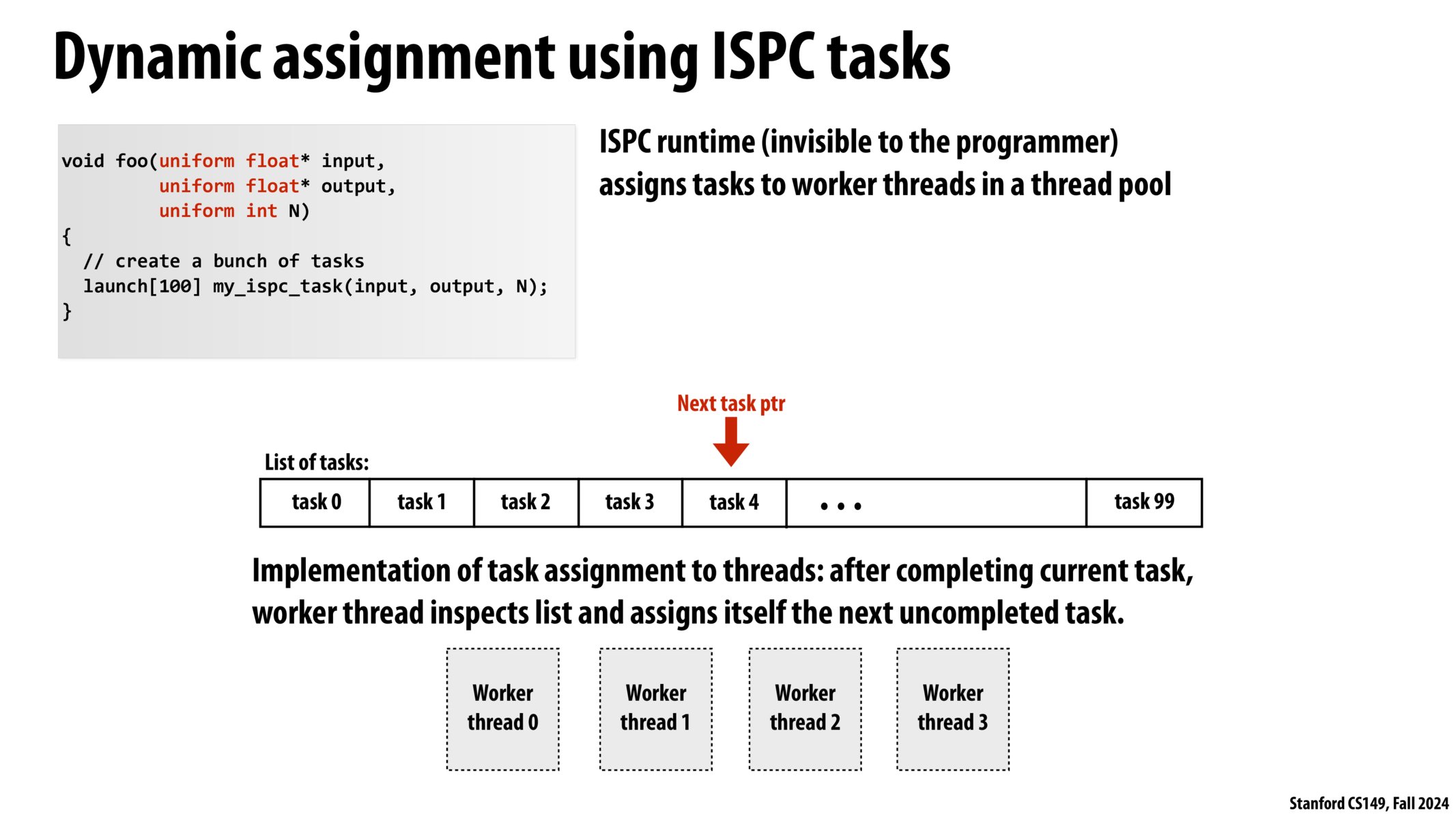
有时候,即使你把任务分解为两个部分,
这些并行工作单元仍然需要同步操作,
以确保每个任务只分配给一个单元,
并且每个工作单元都能得到下一个任务。在之前的三个测试用例中,
线程池的版本比单线程要慢,
因为我的线程在获取下一个任务时需要同步
Orchestration 编排
- 涉及:
- 构建通信
- 必要时添加同步以保留依赖关系
- 在内存中组织数据结构
- 调度任务
- 目标:降低通信/同步成本,保持数据引用的局部性,减少开销等。
- 机器细节会影响其中许多决策
- 如果同步操作很昂贵,程序员可能会更少地使用它
映射 Mapping
- 将“线程”(“工作者”)映射到硬件执行单元
- 示例 1:操作系统映射
- 例如,将
线程映射到 CPU 核心上的硬件执行上下文
- 例如,将
- 示例 2:编译器映射
- 将 ISPC
程序实例映射到向量指令通道(vector instruction lanes)
- 将 ISPC
- 示例 3:硬件映射
- 将 CUDA 线程块映射到 GPU 内核(在未来的讲座中讨论)
- 许多有趣的映射决策:
- 将相关线程(协作线程)放置在同一核心上(最大限度地提高局部性、数据共享、最大限度地降低通信/同步成本)
- 将不相关的线程放在同一个核心上(一个可能是带宽有限的,另一个可能计算有限),以更有效地使用机器
案例:一个并行程序
基于二维网格的求解器
求解器 solver
求解器是一种数学软件,可能以独立计算机程序的形式或作为软件库,用于“解决”数学问题。求解器以某种通用形式获取问题描述并计算其解。在求解器中,重点是创建一个可以轻松应用于其他类似问题的程序或库。
最优解
就像很多高等函数很难求最大值和最小值,
那就只能“一个点一个点尝试”,
直到找到一个“极值”,
这个值就可以作为局部最优解。
收敛
就像牛顿迭代法求平方根一样,
我们不断迭代计算,
如果最后两次结果差距越来越小(|f(n)-f(n-1)| < epsilon)
直到达到我们所要求的精度差,
那么就称这个迭代是收敛的。

- 问题:求解(N+2)x(N+2”网格上的偏微分方程(PDE)
- 解决方案使用迭代算法:
- 在网格上执行高斯-赛德尔扫描,直到收敛
求解算法的伪代码如图:

任何事情的第一步,当我展示代码时我就是在问你:哪些部分可以并行处理?
难点在于,每个点的计算都依赖于它的四个邻居。
而这些邻居有的更新了,有的没更新。
具体而言,一个点(不是边缘点)的左边和上边位置的值是已经更新了的,右边和下边则没有更新。
依赖关系是由左上角传递到右下角的。
步骤 1:确定依赖关系(问题分解阶段)
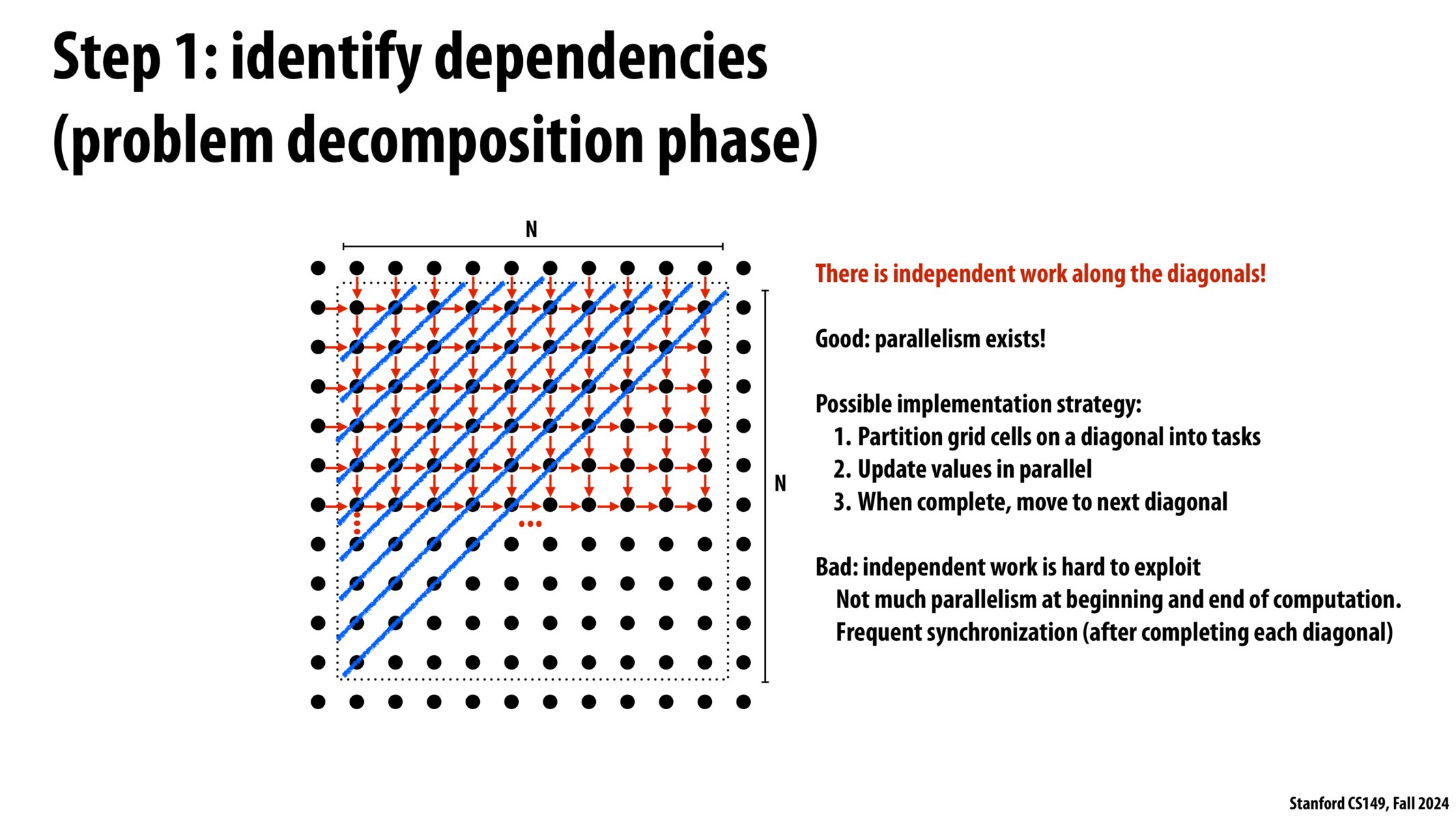
- 沿对角线有一定的并行性!
- 我们可以把每条对角线的运算作为一个 task 来进行任务分解
- 缺点:
- 在开头和结尾的并行数太低了!
- 频繁的同步操作!
且不说我想不想写这种(屎山)代码,这种分解方式:
- 并行数太少了,根据阿姆达定律,可能性能提升很不明显。
- 沿着对角线访问内存,缓存命中率可能很低!
这种思考是我们需要做的最重要的部分!
当我们在今年(2023)作业 4 中做一个小型 Transformer 时,
这将成为其中很大一部分。
有时候你看着一个程序会想:
我真的不想费心去处理这个,
这不是一个我会取得很大成功的程序。
选择另一种求解器
你需要修改算法,不能使用原始的高斯-赛德尔算法,
而是要找到一种更适合并行化计算的算法!
是的,我们需要高斯-赛德尔方法的专业领域知识(而这是并行编程中的一种常见技术)

让我们尝试用新的算法来获得更好的并行化支持!
- 新方法:红黑色块
- 红黑色块不断地交替进行运算,一轮红、一轮黑,并行性很好!
虽然实际上,这个算法收敛速度更慢。
但,我们似乎没别的办法了
分块还是交错?
现在,有一个新的问题,假如我们按行分配任务,
假设分给 4 个并行单元,
- 分块分配:把矩阵平均分成四大块,每块交给一个单元处理
- 交错分配:按行号 i 分配任务,
j = i mod 4,那么第 i 行分给计算单元 j
注意到,分块的方式减少了不同单元之间的数据交换发生,
它们只有边界的行才需要依赖相邻单元的数据。
而在交错分配方式中,每一行都要依赖相邻的其他单元的数据。
所以,分块的方式看起来更不错。
请注意,我们在之前的 sinx 程序中的最佳分配方式是不同的。
情况不同,结论就不同!
两种方式:去考虑编写程序
- 数据并行思考
- 完全不考虑多线程和总体并行化,只是考虑任务的并行化
- SPMD / 共享地址空间
- 这是我的所有工人,然后这是他们如何进行通信并解决问题
求解器的数据并行化表达
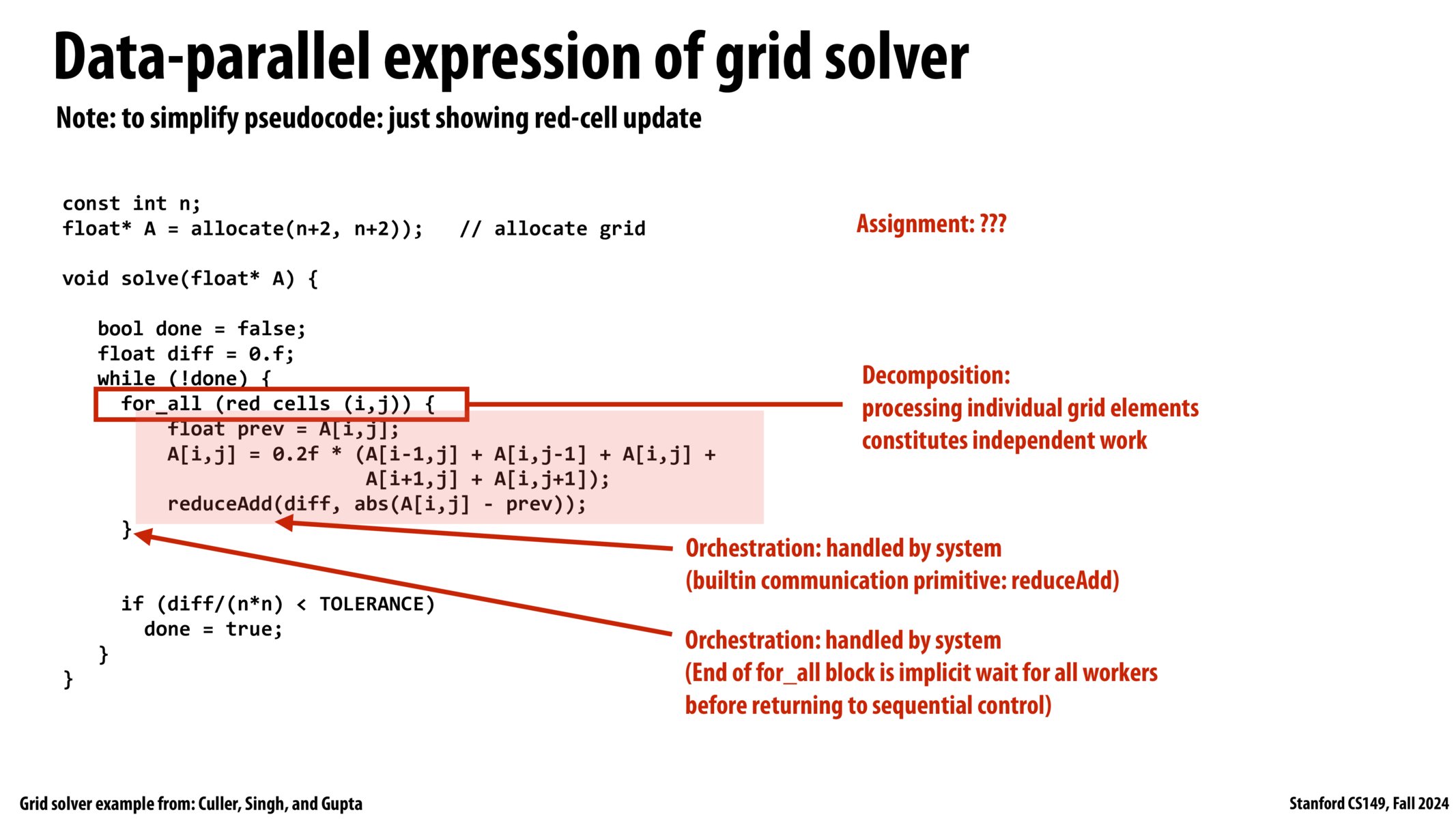
[!NOTE]
这是伪代码,我们现在只是在抽象地思考问题。
我们先跳出 ISPC、SPMD、SIMD 等具体的东西。
最初,代码看起来是顺序迭代的,但我们稍加改动
- 分解:
for_all (red cells (i, j)),遍历红色点而不是全部点
- 分配:??
- 编排:
- 内置通信原语:
reduceAdd for_all块的结束是隐式等待所有 workers 返回顺序控制
- 内置通信原语:
求解器的共享地址空间(使用 SPMD 线程)写法
我们有一个地址空间,
我们不得不用一些手段来进行同步(比如锁和屏障)。
- 程序员负责同步
- 常见同步原语:
- 锁(提供互斥):在不稳定的区域,一次只能有一个线程
- 屏障:等待线程到达这一点
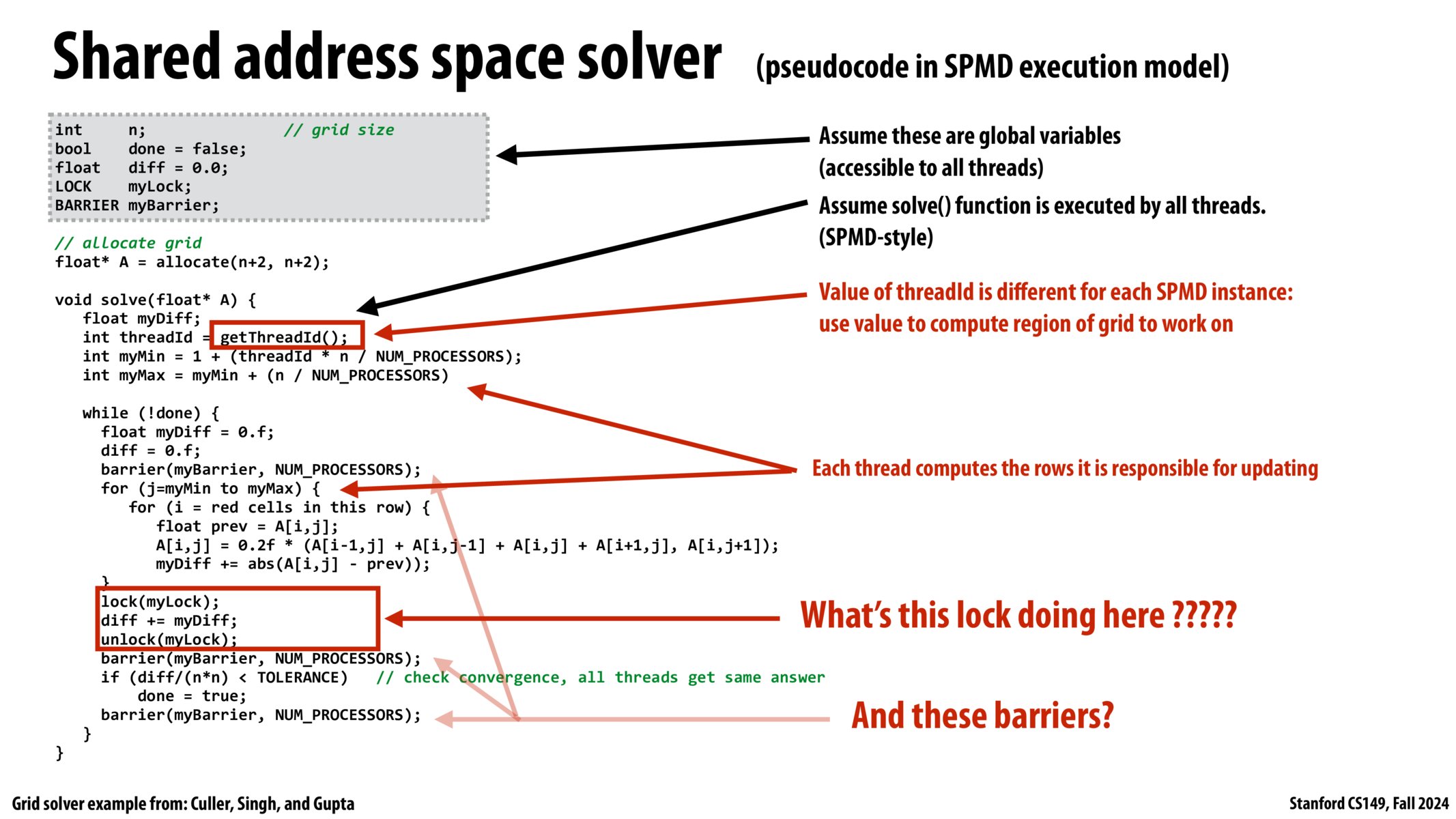
- 不同的程序实例有相同的代码和地址空间
- 但不同程序实例的 id 是不同的,靠 id 来区分他们的任务
- 使用
getThreadId()获取线程 id。- 在(N+2)*(N+2)网格上,对于 id 为 x 的线程,它分到的行号为
1 + (x*n/p), 1 + ((x+1)\*n/p),其中 p 为处理器个数
- 在(N+2)*(N+2)网格上,对于 id 为 x 的线程,它分到的行号为
- 加锁:防止
diff+=myDiff的竞态条件导致错误我们需要确保对这个共享变量的修改操作是原子操作
- 具体来说,多线程读写(这里是加和)可能会导致错过一次(或多次)写回
本课程之后会讲解其他原语来解决竞态条件
- 性能问题:部分和应该在何时进行?(减少同步操作)
- 这个代码已经是改进过的版本了,原始代码中没有
myDiff变量,而是直接在最内层循环对diff进行加和,那样会导致过多的同步操作 回想:“如果同步操作很昂贵,程序员可能会更少地使用它”
- 这个代码已经是改进过的版本了,原始代码中没有
- 屏障(Barrier):
屏障是同步的另一种形式。屏障是一种非常粗粒度的同步框架。
- 所有线程都不能越过一个屏障,直到所有的线程都运行到这个屏障为止。
屏障保证没有线程可以“偷跑”,必须等待大家到齐,一起越过屏障。
- 屏障 1:
- 确保所有线程都执行完
diff=0.0,再进行下一轮的diff加和。 - 如果没有屏障 1,可能某个线程运行非常快,已经计算完毕
myDiff并把它加给了diff。然而,有的线程可能正准备进行清零diff=0.0,导致丢失部分和。
- 确保所有线程都执行完
- 屏障 2:
- 确保执行收敛检查之前,所有的线程都完成了这一轮的算法(最重要的,完成了差错的总和
diff+=mydiff) - 如果没有屏障 2,结果可能不正确。(在
diff+=mydiff总和完成之前,某个线程就执行了收敛检查,导致判断为收敛)
- 确保执行收敛检查之前,所有的线程都完成了这一轮的算法(最重要的,完成了差错的总和
- 屏障 3:
- 确保所有线程执行收敛检查完毕,才执行下一轮的
diff=0.0 - 如果没有屏障 3,可能某个线程跑到了下一次循环执行了
diff=0.0,但还有线程正要进行收敛检查,导致判断为收敛。
- 确保所有线程执行收敛检查完毕,才执行下一轮的
- 挑战:能否只用一个屏障来避免这些竞态条件?
- (提示:借鉴上文说到的
myDiff变量优化思路) - (提示 2:这些线程在竞争什么?)
- (提示:借鉴上文说到的
一个屏障
我们在代码中引入了 不必要的依赖,
因为我每次迭代都重复使用 一个变量 来实现 多个目的
多个目的:
- 清零
diff = 0.0 - 加和
diff += mydiff - 收敛检查
diff/(n*n) < TOLERANCE
- 清零
回想:屏障的作用
- 屏障 1:隔离
diff = 0.0和diff += mydiff - 屏障 2:隔离
diff += mydiff和收敛检查 - 屏障 3:隔离
收敛检查和 下一轮的diff = 0.0
- 屏障 1:隔离
我们使用多个地址空间,替代原本只有一个的全局变量 diff。
那么,我们需要几个 diff 呢?
最朴素的想法是:使用与循环次数相同的 diff 数量。
然而,循环的终止条件与迭代次数无关,只取决于收敛与否,因此这个数没法提前确定。
那贸然给一个足够大的确定数呢,就太浪费空间了。
去除屏障 3:
为了隔离本轮的 收敛检查 和 下一轮的 diff=0.0,至少需要 2 个 diff 交错来使用。
(比如奇数次用 diff1,偶数次用 diff2。)
这时,我们就避免了下一轮的清零(diff2=0.0)影响本轮的检查(检查 diff1)。
那屏障 1 此时能否去掉?
去除屏障 1:
现在我们有 2 个 diff,假设去掉屏障 1.
- 本轮使用
diff1完成收敛检查后,
下一轮使用diff2,执行diff2=0.0 - 如果去掉
屏障1,
仍然可能会有线程率先完成计算diff2 += mydiff,
然后接着有慢腾腾的线程才执行diff2 = 0.0,
导致丢失计算信息。
但是,diff2 += mydiff 和 diff2 = 0.0 发生在同一轮次,不管多少个 diff 都解决不了这个问题。
因此,我们要 修改代码:
- 增加
diff3 - 修改
diff2 += mydiff和diff2 = 0.0,其中一个要使用diff3
这对不对呢?不妨假设修改了 diff2 = 0.0 为 diff3 = 0.0。
我们仍然从唯一的那个屏障开始分析:
- 某一轮,使用
diff1完成了收敛检查 - 下一轮,执行
diff3 = 0.0,并使用diff2 += mydiff计算总和 - 显然,三个操作使用三个不同的全局变量,且有一个屏障保证多线程不会相差超过上下两个周期,消除了竞态条件。
- 一个问题:
diff2是在什么时候被清零的?- 因为
diff3 = 0.0和diff2 += mydiff发生在同一轮 - 也就是说,
diff[(i+1) % 3] = 0.0和diff[i] += mydiff发生在同一轮 - 因此
diff2 = 0.0和diff1 += mydiff发生在同一轮。
- 因为
最终,我们增加了 2 个全局变量,减少了 2 个屏障,获得了性能提升。

其五:Performance Optimization I: Work Distribution and Scheduling
性能优化 1:工作分配和调度
摘要:实现良好的工作分配,同时最小化开销,使用工作窃取来调度 Cilk 程序
高性能编程
- 优化并行程序的性能是一个不断迭代的过程,改进
分解 decomposition、分配 assignment和编排 orchestration的选择 - 关键目标(相互矛盾)
- 在可用的执行资源上平衡工作负载
- 减少通信(避免停顿)
- 减少因为提高并行性、管理分配、减少通信等而执行的额外工作(开销)。
[!TIP]
Always implement the simplest solution first, then measure performance to determine if you need to do better.始终先实施最简单的解决方案,然后衡量性能以确定是否需要做得更好。
Kayvon:因为在一些编程作业中,很多学生一开始就奔着复杂化、并行化、“优化”去了,他们花费大部分时间来研究讲义、研究各种技术,构造一个相当复杂的方案。最后,在作业截止前三四天,他们说“只需要把它编码出来,能运行,它就会表现得很好”。结果往往是,复杂的方案比简单的方案更慢。
平衡工作负载
理想情况下:在程序执行期间,所有处理器都在进行计算
(他们同时(simultaneously)进行计算,同时(at the same time)完成各自的工作)
- 假设有 4 个处理器处理 4 个任务,花费时间为:
- p1: 1 mins
- p2: 1 mins
- p3: 1 mins
- p4: 2 mins
p4 花费多一倍的时间,所以按照阿姆达定律:
- 加速比
Sn = 1 / (1 - a + a/p), - 其中
a = 4 / 5 = 0.8(可串行化部分占比) - 其中
p = 4(4 个处理器) - 所以
Sn = 1 / (1 - 0.8 + 0.8/4) = 1/0.4 = 2.5
如果我们能完全平均分配任务,加速比应当是 4 倍。
静态分配(Static assignment)
- 分配不一定发生在编译时(compile-time)
- 之所以叫 静态,是因为 工作(work) 量和 工作者 数量是确定的
- 分配还取决于运行时参数:输入数据的规模、线程数,等等。
- 回忆编程作业 1,程序 1:为每个线程分配相同数量的网格单元 – 学生探索不同的静态工作分配给工人
- 静态赋值的优点:执行赋值的简单、基本上为零的运行时开销(在本例中:实现赋值的工作有点像索引数学)
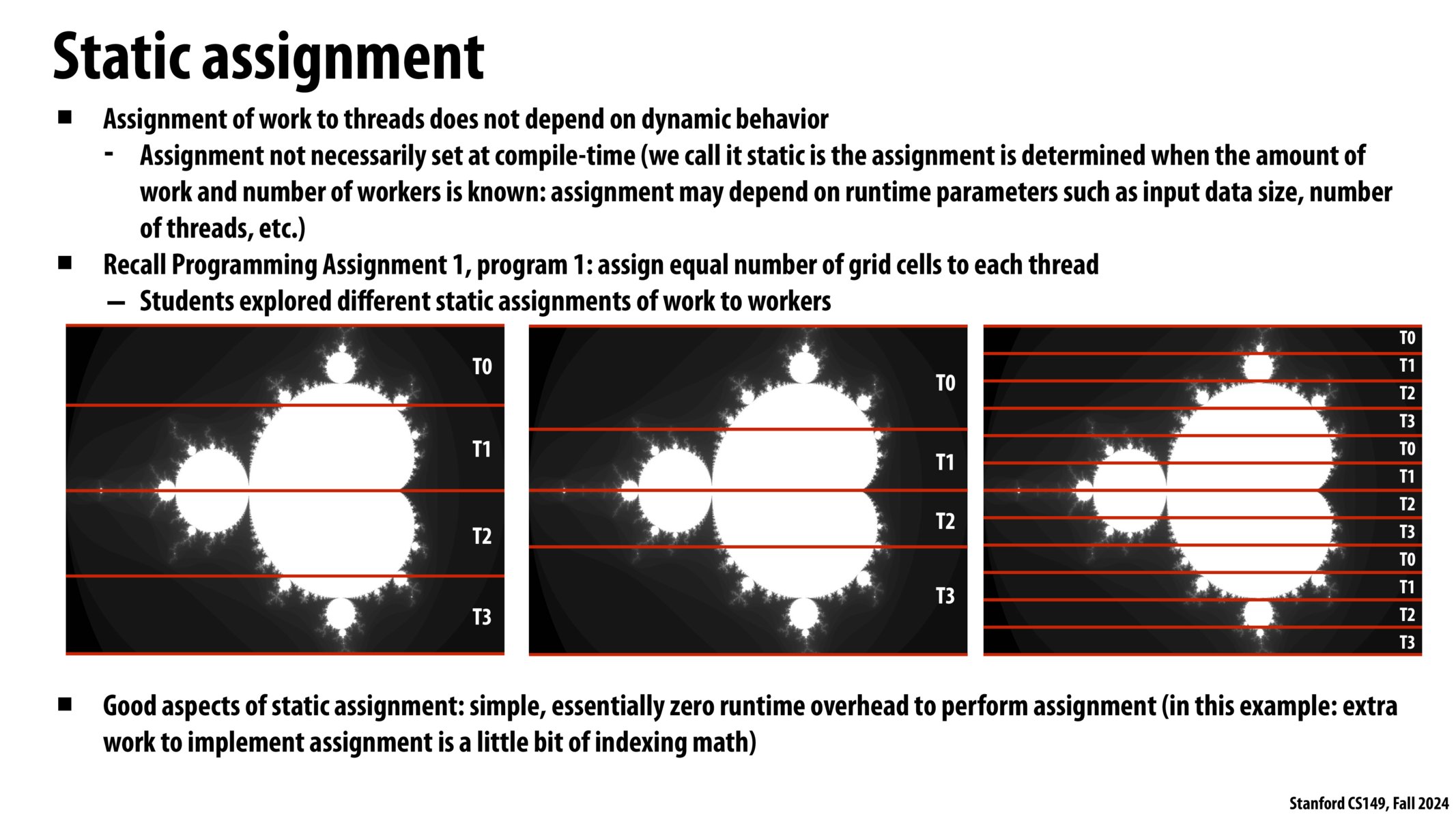
- 平均区域划分
- 分形划分
- 交错分配
什么时候静态分配更适用?
- 当工作的成本(执行时间)和工作量是可预测的时候,允许程序员提前制定一个好的分配(assignment)
- 当工作是可预测的,但并非所有工作都有相同的成本时
- 当执行时间的统计数据是可预测的(例如,平均成本相同)
“半静态”分配
- 近期的工作成本是可以预测的
- idea:最近的过去可以很好地预测不久的将来
- 应用程序定期分析其执行情况并重新调整分配
- 对于重新调整之间的间隔,分配是“静态的”
- 粒子模拟:当粒子在模拟过程中移动时,将粒子重新分配给工作者
- 自适应网格:网格随着对象移动或对象上的流动而变化,
模拟过程但变化缓慢
